每一个程序员都应该了解的内存知识-Part9
附录和参考书目
注:本文由 Kimi AI 翻译
9 附录和参考文献
9.1 矩阵乘法
这是第6.2.1节中矩阵乘法的完整基准程序。有关所用内联函数的详细信息,请参阅Intel的参考手册。
1 | |
循环结构与第6.2.1节中的最终版本大致相同。最大的变化是加载 rmul1[k2] 的值已经从内循环中提取出来,因为我们必须创建一个向量,其中两个元素具有相同的值。这就是 _mm_unpacklo_pd() 内联函数的作用。
另一个值得注意的是,我们显式对齐了三个数组,以确保我们期望在同一缓存行中的值实际上确实在那里。
9.2 调试分支预测
如果按照第6.2.2节的建议使用 likely 和 unlikely 的定义,使用GNU工具链很容易有一个调试模式来检查假设是否真的成立。宏的定义可以替换为以下内容:
1 | |
这些宏使用GNU汇编器和链接器提供的大量功能,在创建ELF文件时。DEBUGPRED 情况下的第一个 asm 语句定义了三个额外的节;它主要向汇编器提供有关如何创建节的信息。所有节在运行时都是可用的,predict_data 节是可写的。重要的是所有节名称都是有效的C标识符。原因很快就会清楚。
新的 likely 和 unlikely 宏的定义引用了特定于机器的 debugpred__ 宏。这个宏有以下任务:
在
predict_data节中分配两个词以包含正确和不正确预测的计数。这两个字段通过使用%=获得唯一名称;前导点确保符号不会污染符号表。在
predict_line节中分配一个词以包含likely或unlikely宏使用的行号。在
predict_file节中分配一个词以包含likely或unlikely宏使用的文件名的指针。根据表达式
e的实际值增加为此宏创建的“正确”或“不正确”计数器。我们这里不使用原子操作,因为它们要慢得多,而且在发生冲突的不太可能的情况下绝对精度不是那么重要。如果需要,很容易更改。
.pushsection 和 .popsection 伪操作在汇编器手册中有描述。感兴趣的读者被要求使用手册和一些试错来探索这些定义的细节。
这些宏自动且透明地处理收集关于正确和不正确分支预测的信息。缺少的是如何获取结果的方法。最简单的方法是为对象定义一个析构函数并在其中打印结果。这可以通过像这样定义的函数实现:
1 | |
这里,节名称是有效的C标识符这一事实得到了应用;它被GNU链接器用来自动定义(如果需要的话)两个节的符号。__start_XYZ 符号对应于节 XYZ 的开始,而 __stop_XYZ 是节 XYZ 之后的第一个字节的位置。这些符号使得在运行时可以迭代节内容。请注意,由于节的内容可能来自链接器在链接时使用的所有文件,因此编译器和汇编器没有足够的信息来确定节的大小。只有通过这些神奇的链接器生成的符号,才能迭代节内容。
代码不仅仅迭代一个节;而是涉及三个节。由于我们知道,对于 predict_data 节中添加的每两个字,我们向 predict_line 和 predict_file 节各自添加一个字,我们不必检查这两个节的边界。我们只需携带指针并统一递增它们。
代码为代码中出现的每个预测打印出一行。它突出显示了预测不正确的用法。当然,这可以更改,并且调试模式可以限制为仅标记不正确预测多于正确预测的条目。这些是需要更改的候选项。还有一些细节使问题复杂化;例如,如果分支预测发生在在多个地方使用的宏中,则必须一起考虑所有宏用法,然后才能做出最终判断。
最后两个评论:这种调试操作所需的数据不小,而且,在DSOs的情况下,是昂贵的(必须重新定位 predict_file 节)。因此,不应在生产二进制文件中启用调试模式。最后,每个可执行文件和DSO都创建自己的输出,分析数据时必须记住这一点。
9.3 测量缓存行共享开销
本节包含测试程序,用于测量使用同一缓存行上的变量与使用不同缓存行上的变量的开销。
1 | |
代码主要作为示例提供,演示如何编写测量缓存行开销等效果的程序。循环体中的 tf 是有趣的部分。已知编译器的 __sync_add_and_fetch 内联函数生成原子添加指令。在第二个循环中,我们必须“使用”增加的结果(通过内联 asm 语句)。asm 不引入任何实际代码;相反,它防止编译器将增加操作提升出循环。
第二个有趣的部分是程序将线程固定在特定处理器上。代码假设处理器编号为0到3,如果机器有四个或更多逻辑处理器,这通常是这种情况。代码可以使用 libNUMA 接口来确定可用处理器的编号,但是这个测试程序应该在不引入此依赖性的情况下广泛可用。很容易以这样或那样的方式进行修复。
10 OProfile技巧
以下不是关于如何使用oprofile的教程。关于这个主题已经写了很多文档。相反,它旨在提供一些更高层次的提示,如何查看自己的程序以找到可能的问题点。但在那之前,我们至少必须有一个关于oprofile的最小介绍。
10.1 Oprofile基础知识
Oprofile的工作分为两个阶段:收集然后分析。收集由内核执行;它不能在用户级别完成,因为测量使用CPU的性能计数器。这些计数器需要访问MSRs,这反过来又需要特权。
每个现代处理器都提供自己的性能计数器集。在某些架构上,所有处理器实现都提供了计数器的一个子集,而其他计数器则因版本而异。这使得给出关于使用oprofile的一般建议变得困难。还没有(尚未)一个更高层次的抽象来隐藏这些细节。
处理器版本还控制着任何时候可以跟踪的事件数量,以及它们的组合方式。这为情况增加了更多的复杂性。
如果用户了解有关性能计数器的必要的详细信息,可以使用opcontrol程序来选择要计数的事件。对于每个事件,需要指定“溢出编号”(在记录事件之前必须发生的事件数量),事件是否应计入用户级别和/或内核,最后是“单元掩码”(它选择性能计数器的子功能)。
要在x86和x86-64处理器上计数CPU周期,必须发出以下命令:
1 | |
数字30000是溢出编号。选择一个合理的值对于系统的行为和收集的数据很重要。要求接收有关事件的每个发生的数据是一个坏主意。对于许多事件,这将使机器停止运行,因为它将只工作在数据收集事件溢出上;这就是为什么oprofile强制执行最小值的原因。不同事件的最小值不同,因为不同事件在正常代码中被触发的概率不同。
选择一个非常高的数字会降低概要文件的分辨率。在每个溢出处,oprofile会记录此时执行的指令的地址;对于x86和PowerPC,在某些情况下,它还可以记录回溯。{回溯支持有望在某个时候对所有架构都可用。} 通过粗略分辨率,热点可能不会获得代表性的命中数;这一切都是关于概率,这就是为什么oprofile被称为概率分析器。溢出编号越低,对系统的影响就越大,就减速而言,但分辨率越高。
如果要分析特定程序,并且系统不用于生产,通常最有用的是使用尽可能低的溢出值。每个事件的确切值可以使用查询:
1 | |
如果被分析程序与另一个进程交互,并且减速导致交互出现问题,则可能会出现问题。如果进程有一些实时要求,在经常被中断时无法满足,那么必须找到中间地带。如果整个系统要在长时间内进行分析,情况也是如此。一个低的溢出编号将意味着巨大的减速。在任何情况下,oprofile和任何其他分析机制一样,都会引入不确定性和不准确性。
分析必须使用 opcontrol --start 启动,并且可以用 opcontrol --stop 停止。当oprofile处于活动状态时,它会收集数据;这些数据首先在内核中收集,然后以批次发送到用户级守护程序,在那里进行解码并写入文件系统。使用 opcontrol --dump 可以请求将内核中缓冲的所有信息释放到用户级。
收集的数据可以包含来自不同性能计数器的事件。除非用户选择在单独的oprofile运行之间清除存储的数据,否则所有数字都保持并行。可以在同一事件的不同场合累积数据。如果在不同的分析运行期间遇到事件,则如果用户选择这样做,数字将被累加。
用户级数据收集过程的后半部分将数据多路分解。每个文件的数据单独存储。甚至可以区分由各个可执行文件使用的DSOs,甚至可以区分个别线程的数据。通过这种方式产生的数据可以使用 oparchive 进行归档。由此命令生成的文件可以传输到另一台机器上,然后在那里进行分析。
使用opreport程序可以从分析结果生成报告。使用opannotate可以查看各种事件发生的位置:哪个指令,如果数据可用,在哪个源代码行。这使得找到热点变得容易。计数CPU周期将指出大部分时间花费在哪里(包括缓存未命中),而计数退休指令则允许找到大部分执行指令的位置——这两者之间有很大的差异。
单个命中一个地址通常没有意义。统计分析的一个副作用是,只执行几次,甚至只执行一次的指令,可能会被归因于一个命中。在这种情况下,通过重复验证结果是非常必要的。
10.2 它看起来像什么
一个oprofile会话可以像这样简单:
1 | |
请注意,包括实际程序在内的这些命令都是以root身份运行的。这里以root身份运行程序只是为了简单起见;程序可以由任何用户执行,oprofile会注意到它。下一步是分析数据。使用opreport我们可以看到:
1 | |
这意味着我们收集了一堆事件;现在可以使用opannotate以更详细地查看数据。我们可以看到程序中记录了最多事件的位置。opannotate --source输出的一部分看起来像这样:
1 | |
这是测试的内部函数,大部分时间都花在这里。我们看到样本分布在循环的所有三行上。这主要是因为采样并不总是100%准确地记录记录的指令指针。CPU执行指令的顺序可能会变化;重建确切的执行顺序以产生正确的指令指针是很难的。最新的CPU版本尝试为少数事件这样做,但通常情况下,这并不值得努力——或者根本不可能。在大多数情况下,这并不重要。即使存在正态分布的样本集,程序员也应该能够弄清楚发生了什么。
10.3 开始分析
当开始分析一段代码时,我们当然可以从程序中花费最长时间的地方开始。那段代码当然应该尽可能地优化。但接下来会发生什么呢?程序在哪里花费了不必要的时间?
这个问题不容易回答。
这种情况下的一个问题是,绝对值并不说明真实情况。程序中的一个循环可能需要大部分时间,这是可以的。高CPU利用率有很多可能的原因。但更常见的是,CPU使用率更均匀地分布在整个程序中。在这种情况下,绝对值指向许多地方,这是没有用的。
在许多情况下,查看两个事件的比率是有帮助的。例如,一个函数中错误预测的分支数量如果没有对函数执行频率的度量,那么这个绝对值就没有意义。是的,绝对值与程序的性能相关。每次调用错误预测的比率对函数的代码质量更有意义。Intel的x86和x86-64优化手册[intendopt]描述了应该调查的比率(引用文档的核心2事件附录B.7)。与内存处理相关的一些相关比率如下。
| 指令获取暂停 | CYCLES_L1I_MEM_STALLED /CPU_CLK_UNHALTED.CORE |
由于缓存或ITLB未命中,导致指令解码器等待新数据的周期比率。 |
| ITLB未命中率 | ITLB_MISS_RETIRED / INST_RETIRED.ANY |
每个指令的ITLB未命中。如果此比率高,则代码分布在太多页面上。 |
| L1I未命中率 | L1I_MISSES / INST_RETIRED.ANY |
每个指令的L1i未命中。执行流是不可预测的或代码大小太大。在前一种情况下,避免间接 跳转可能会有所帮助。在后一种情况下,块重新排序或避免 内联可能会有所帮助。 |
| L2指令未命中率 | L2_IFETCH.SELF.I_STATE /INST_RETIRED.ANY |
每个指令的L2未命中程序代码。任何大于零的值表明代码局部性问题比L1i未命中更严重。 |
| 装载率 | L1D_CACHE_LD.MESI / CPU_CLK_UNHALTED.CORE |
每个周期的读取操作。Core 2核心可以服务一个装载 操作。高比率意味着执行受内存 读取限制。 |
| 存储顺序阻塞 | STORE_BLOCK.ORDER /CPU_CLK_UNHALTED.CORE |
由于先前的存储未命中缓存,存储被阻塞的比率。 |
| L1d阻塞加载率 | LOAD_BLOCK.L1D /CPU_CLK_UNHALTED.CORE |
由于缺乏资源,L1d阻止的加载。通常这意味着太多的并发L1d访问。 |
| L1D未命中率 | L1D_REPL / INST_RETIRED.ANY |
每个指令的L1d未命中。高比率意味着预取无效,L2使用得太频繁。 |
| L2数据未命中率 | L2_LINES_IN.SELF.ANY /INST_RETIRED.ANY |
每个指令的数据L2未命中。如果值显著 大于零,则硬件和软件预取无效。处理器需要更多(或更早)的软件预取帮助。 |
| L2需求未命中率 | L2_LINES_IN.SELF.DEMAND /INST_RETIRED.ANY |
硬件预取器根本没有使用的每个指令的数据L2未命中。这意味着,预取甚至还没有开始。 |
| 有用的NTA预取率 | SSE_PRE_MISS.NTA /SSS_PRE_EXEC.NTA |
相对于所有非时间性预取的总数,有用的非时间性预取的比率。低值意味着许多值已经在缓存中。这个比率也可以为其他预取类型计算。 |
| 晚期NTA预取率 | LOAD_HIT_PRE / SSS_PRE_EXEC.NTA |
相对于所有非时间性预取的总数,具有正在进行的预取的数据的加载请求的比率。高值意味着软件预取指令发出得太晚了。这个比率也可以为其他预取类型计算。 |
对于所有这些比率,程序应该运行时指导oprofile测量两个事件。这保证了两个计数是可比较的。在除法之前,必须确保考虑了可能不同的溢出值。最简单的方法是通过将每个事件的计数乘以溢出值来确保这一点。
这些比率对于整个程序、可执行文件/DSO级别,甚至函数级别都是有意义的。越深入地查看程序,包含在值中的错误就越多。
为了使比率有意义,需要基线值。这并不像看起来那么简单。不同类型的代码具有不同的特性,一个程序中的比率值可能很糟糕,而在另一个程序中可能是正常的。
11 内存类型
尽管对于高效编程并非必要知识,但描述一些内存类型的更多技术细节可能是有用的。具体来说,我们在这里感兴趣的是“注册”与“未注册”以及ECC与非ECC DRAM类型之间的区别。
“注册”和“缓冲”这两个术语在描述带有DRAM模块上一个额外组件的DRAM类型时可以互换使用:一个缓冲区。所有DDR内存类型都可以是注册和未注册的形式。对于未注册的模块,内存控制器直接连接到模块上的所有芯片上。图11.1显示了设置。
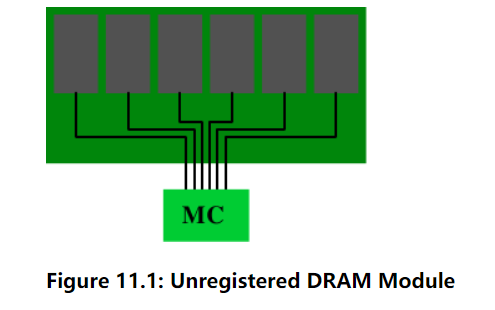
图11.1:未注册的DRAM模块
从电气角度来看,这是相当苛刻的。内存控制器必须能够处理所有内存芯片的容量(图中显示的六个芯片以上)。如果内存控制器(MC)有限制,或者要使用许多内存模块,这种设置并不理想。
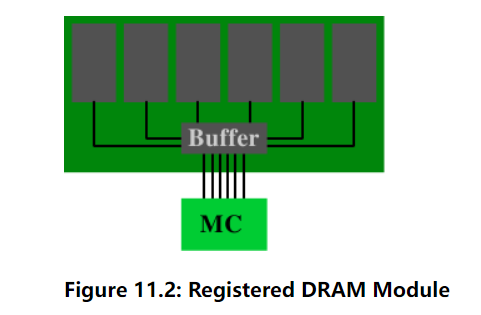
图11.2:注册DRAM模块
缓冲(或注册)内存改变了这种情况:RAM芯片不是直接连接到DRAM模块上的内存,而是连接到一个缓冲区,然后该缓冲区再连接到内存控制器。这显著降低了电气连接的复杂性。内存控制器驱动DRAM模块的能力增加了与节省的连接数相对应的因子。
有了这些优势,问题是:为什么不是所有的DRAM模块都是缓冲的?有几个原因。显然,缓冲模块有点复杂,因此更昂贵。成本不是唯一的因素。缓冲区稍微延迟了来自RAM芯片的信号;延迟必须足够长,以确保来自RAM芯片的所有信号都被缓冲。结果是,DRAM模块的延迟增加了。这里值得一提的最后一个因素是,额外的电子元件增加了能源成本。由于缓冲区必须以总线频率运行,因此该组件的能源消耗可能相当大。
考虑到DDR2和DDR3模块的其他因素,通常不可能每个存储体有超过两个DRAM模块。内存控制器的引脚数量限制了存储体的数量(在商品硬件中为两个)。大多数内存控制器能够驱动四个DRAM模块,因此未注册模块就足够了。在具有高内存需求的服务器环境中,情况可能会有所不同。
服务器环境的另一个方面是它们不能容忍错误。由于RAM单元中电容器保持的微小电荷,可能会出现错误。人们经常开玩笑说宇宙辐射,但这确实是可能的。加上阿尔法衰变和其他自然现象,它们导致RAM单元中的内容从0变为1或反之亦然。使用的内存越多,发生此类事件的可能性就越大。
如果这样的错误是不可接受的,可以使用ECC(错误校正码)DRAM。错误校正码使硬件能够识别不正确的单元内容,并在某些情况下纠正错误。在旧时代,奇偶校验只识别错误,并且当检测到错误时必须停止机器。有了ECC,相反,少量的错误位可以自动纠正。如果错误数量太多,则无法正确执行内存访问,机器仍然会停止。然而,对于工作DRAM模块来说,这种情况相当不可能,因为必须在同一模块上发生多个错误。
当我们谈论ECC内存时,我们实际上并不完全正确。不是内存执行错误检查;相反,是内存控制器。DRAM模块只是提供更多的存储,并与实际数据一起传输额外的非数据位。通常,ECC内存存储每8位数据的1位额外位。为什么使用8位将在后面解释。
在将数据写入内存地址时,内存控制器在将数据和ECC传输到内存总线之前,会实时计算新内容的ECC。当读取时,接收到数据和ECC,内存控制器计算数据的ECC,并将其与从DRAM模块传输的ECC进行比较。如果ECC匹配,一切正常。如果不匹配,内存控制器尝试纠正错误。如果无法进行此纠正,则记录错误,机器可能会停止。
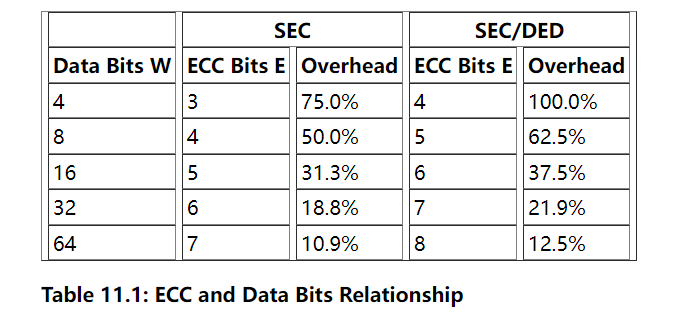
表11.1:ECC和数据位的关系
几种错误校正技术在使用中,但对于DRAM ECC,通常使用汉明码。汉明码最初用于使用能够识别和纠正一个翻转位(SEC,单错误校正)的能力对四个数据位进行编码。该机制可以轻松扩展到更多的数据位。数据位W的数量与错误代码位E的数量之间的关系由方程描述
E = ⌈log2 (W+E+1)⌉
迭代求解这个方程得到表11.1第二列中的值。通过增加一个位,我们可以使用一个简单的奇偶校验位识别两个翻转位。这被称为SEC/DED,单错误校正/双错误检测。通过这个额外的位,我们得到了表11.1第四列中的值。对于W=64的开销足够低,数字(64,8)是8的倍数,所以这是ECC的一个自然选择。在大多数模块上,每个RAM芯片产生8位,因此任何其他组合都会导致不太有效的解决方案。

图11.3:汉明生成矩阵构造
使用W=4和E=3的代码可以轻松演示汉明码计算。我们在编码字的战略位置计算奇偶校验位。图11.3显示了原则。在对应于二的幂的位位置上添加了奇偶校验位。第一个奇偶校验位P1的奇偶校验和包含每第二个位。第二个奇偶校验位P2的奇偶校验和包含数据位1、3和4(这里编码为3、6和7)。类似地计算P4。

可以使用矩阵乘法更优雅地描述奇偶校验位的计算。我们构造一个矩阵G = [I|A],其中I是单位矩阵,A是我们可以从图11.3中确定的奇偶校验生成矩阵。现在,如果我们将每个输入数据项表示为一个4维向量d,我们可以计算r=d⋅G并得到一个7维向量r。这就是在ECC DDR的情况下存储的数据。
要解码数据,我们构造一个新的矩阵H=[AT|I],其中AT是计算G时的奇偶校验生成矩阵的转置。这意味着:
H⋅r的结果显示存储的数据是否有缺陷。如果没有,乘积是三维向量(0 0 0)T。否则,乘积的值,当解释为数字的二进制表示时,表示翻转位的列号。内存控制器可以纠正该位,程序将不会注意到存在问题。
处理DED部分的额外位只是稍微复杂一些。通过更多的努力,可以创建可以纠正两个翻转位甚至更多的代码。是概率和风险决定是否需要这样做。一些内存制造商表示,每750小时可以在256MB的RAM中发生一次错误。通过加倍内存量,时间减少了75%。有足够的内存,在短时间内经历错误的概率可以是显著的,ECC RAM成为必需。时间框架甚至可能如此之小,以至于SEC/DED实现甚至不足够。
而不是实现更多的错误校正能力,服务器主板有能力在给定的时间框架内自动读取所有内存。这意味着,无论内存是否实际被处理器请求,内存控制器都会读取数据,如果ECC检查失败,则将已纠正的数据写回内存。只要在读取所有内存并将其写回所需的时间框架内发生少于两个内存错误的概率是可以接受的,SEC/DED错误校正是一个完全合理的解决方案。
与注册DRAM一样,必须问的问题是:为什么ECC DRAM不是常态?这个问题的答案与注册RAM的等效问题相同:额外的RAM芯片增加了成本,奇偶校验计算增加了延迟。未注册的,非ECC内存可以显著更快。由于注册和ECC DRAM的问题相似,通常只找到注册的,ECC DRAM,而不是未注册的,非ECC DRAM。
另一种克服内存错误的方法。一些制造商提供所谓的“内存RAID”,其中数据在多个DRAM模块或至少RAM芯片上冗余分布。具有此功能的主板可以使用未注册的DRAM模块,但内存总线上增加的流量可能会抵消ECC和非ECC DRAM模块的访问时间差异。
12 libNUMA介绍
尽管程序员需要的许多信息,如调度线程,适当分配内存等,都是可用的,但获取这些信息却相当繁琐。现有的NUMA支持库(libnuma,在RHEL/Fedora系统上的numactl包中)远未提供足够的功能。
作为响应,作者提出了一个新的库,提供NUMA所需的所有功能。由于内存和缓存层次结构处理的重叠,这个库对于非NUMA系统上的多线程和多核处理器也也很有用——几乎所有当前可用的机器。
这个新库的功能迫切需要遵循本文档中的建议。这就是这里提到它的唯一原因。该库(截至撰写本文时)尚未完成,未经审查,未经打磨,并且未广泛分发。它在未来可能会发生显著变化。它目前在 http://people.redhat.com/drepper/libNUMA.tar.bz2 上可用。
这个库的接口严重依赖于 /sys 文件系统导出的信息。如果该文件系统未挂载,许多函数将简单地失败或提供不准确的信息。如果进程在 chroot 监狱中执行,这一点尤其重要要记住。
库的接口头包含当前以下定义:
1 | |
MEMNODE_* 宏在形式和功能上类似于第6.4.3节中引入的 CPU_* 宏。没有非 _S 变体的宏,它们都需要一个大小参数。memnode_set_t 类型相当于 cpu_set_t,但这次是针对内存节点的。请注意,内存节点的数量不需要与CPU的数量有任何关系,反之亦然。可以有一个内存节点对应多个CPU,甚至没有CPU。因此,动态分配的内存节点位集的大小不应由CPU的数量决定。
相反,应该使用 NUMA_memnode_system_count 接口。它返回当前注册的节点数。这个数字可能会随着时间的推移增长或缩小。然而,通常情况下,它会保持不变,因此是用于大小内存节点位集的好值。分配再次类似于 CPU_ 宏,使用 MEMNODE_ALLOC_SIZE、MEMNODE_ALLOC 和 MEMNODE_FREE 进行。
作为与 CPU_* 宏的最后并行,库还提供了比较内存节点位集是否相等和执行逻辑操作的宏。
NUMA_cpu_* 函数提供处理CPU集的功能。部分接口只是使现有功能以新名称可用。NUMA_cpu_system_count 返回系统中的CPU数量,NUMA_CPU_system_mask 变体返回设置了适当位的位掩码——这是其他方式无法获得的功能。
NUMA_cpu_self_count 和 NUMA_cpu_self_mask 返回有关当前线程当前被允许在其上运行的CPU的信息。NUMA_cpu_self_current_idx 返回当前使用的CPU的索引。
此信息可能在返回时已经过时,由于内核可以做出的调度决策;必须始终假定其不准确。NUMA_cpu_self_current_mask 返回相同的信息,并在位集中设置了适当的位。
NUMA_memnode_system_count 已经介绍过了。NUMA_memnode_system_mask 是等效的函数,它填充一个位集。NUMA_memnode_self_mask 根据线程当前可以运行的任何CPU直接连接的内存节点填充一个位集。
NUMA_memnode_self_current_idx 和 NUMA_memnode_self_current_mask 返回更专门的信息。返回的信息是连接到线程当前正在运行的处理器的内存节点。正如对于 NUMA_cpu_self_current_* 函数一样,当函数返回时,此信息可能已经过时;它只能作为提示使用。
NUMA_cpu_to_memnode 函数可用于将一组CPU映射到直接连接的内存节点集。如果CPU设置中只设置了单个位,则可以确定每个CPU属于哪个内存节点。目前,Linux并不支持单个CPU属于超过一个内存节点;理论上,这在未来可能会改变。为了在另一个方向上进行映射,可以使用 NUMA_memnode_to_cpu 函数。
如果内存已经被分配,有时了解其被分配的位置是有用的。这就是 NUMA_mem_get_node_idx 和 NUMA_mem_get_node_mask 允许程序员确定的。前者返回由参数指定的地址对应的页面被分配的内存节点的索引——或者根据当前安装的策略,如果页面尚未分配,将被分配。第二个函数可以为整个地址范围执行工作;它以位集的形式返回信息。函数的返回值是使用的不同内存节点的数量。
在本节的其余部分,我们将看到这些接口的一些用例示例。在所有情况下,我们跳过错误处理和CPU和/或内存节点的数量对于 cpu_set_t 和 memnode_set_t 类型分别过大的情况。使代码健壮是留给读者作为练习的。
12.1 确定给定CPU的线程兄弟
要调度辅助线程,或者从被调度在给定CPU的线程上受益的其他线程,可以使用以下代码序列。
1 | |
该代码首先为由 cpunr 指定的CPU生成一个位集。然后将此位集与第五个参数一起传递给 NUMA_cpu_level_mask,该参数指定我们正在寻找超线程。结果返回在 hyperths 位集中。剩余要做的就是清除对应于原始CPU的位。
12.2 确定给定CPU的核心兄弟
如果两个线程不应被调度在两个超线程上,但可以从缓存共享中受益,我们需要确定处理器的其他核心。以下代码序列可以完成此操作。
1 | |
代码的第一部分与确定超线程的代码相同。这不是巧合,因为我们必须区分给定CPU的超线程与其他核心。这是通过调用 NUMA_cpu_level_mask 的第二部分实现的,但这次级别为2。剩余要做的就是从结果中移除给定CPU的所有超线程。nhts 和 ncs 变量用于跟踪相应位集中设置的位数。
生成的掩码可用于调度另一个线程。如果不需要显式调度其他线程,则使用核心的决定可以留给操作系统。否则,可以迭代地运行以下代码:
1 | |
循环在每次迭代中从剩余的、使用的核中选择一个CPU编号。然后它计算这个CPU的所有超线程。得到的结果位集然后从可用核的位集中减去(使用 CPU_XOR)。如果XOR操作没有移除任何东西,那么真的出了问题。ncs 变量已更新,我们准备好了下一轮,但在做出调度决定之前,我们还没有准备好。最后,任何 idx、cur 或 hyperths 都可以用来调度线程,这取决于程序的要求。通常最好尽可能让操作系统自由,因此使用 hyperths 位集,以便操作系统可以选择最佳的超线程。
参考文献
- [amdccnuma]
Performance guidelines for amd athlon™ 64 and amd opteron™ ccnuma multiprocessor systems. Advanced Micro Devices, 2006. - [arstechtwo]
Stokes, Jon ``Hannibal’’. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004. - [continuous]
Anderson, Jennifer M., Lance M. Berc, Jeffrey Dean, Sanjay Ghemawat, Monika R. Henzinger, Shun-Tak A. Leung, Richard L. Sites, Mark T. Vandevoorde, Carl A. Waldspurger and William E. Weihl. Continuous profiling: Where have all the cycles gone. Proceedings of the 16th acm symposium of operating systems principles, pages 1–14. 1997. - [dcas]
Doherty, Simon, David L. Detlefs, Lindsay Grove, Christine H. Flood, Victor Luchangco, Paul A. Martin, Mark Moir, Nir Shavit and Jr. Guy L. Steele. DCAS is not a Silver Bullet for Nonblocking Algorithm Design. Spaa ‘04: proceedings of the sixteenth annual acm symposium on parallelism in algorithms and architectures, pages 216–224. New York, NY, USA, 2004. ACM Press. - [ddrtwo]
Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004. - [directcacheaccess]
Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005. - [dwarves]
Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007. - [futexes]
Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf. - [goldberg]
Goldberg, David. What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys, 23(1):5–48, 1991. - [highperfdram]
Cuppu, Vinodh, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133–1153, 2001. - [htimpact]
Margo, William, Paul Petersen and Sanjiv Shah. Hyper-Threading Technology: Impact on Compute-Intensive Workloads. Intel Technology Journal, 6(1), 2002. - [intelopt]
Intel 64 and ia-32 architectures optimization reference manual. Intel Corporation, 2007. - [lockfree]
Fober, Dominique, Yann Orlarey and Stephane Letz. Lock-Free Techiniques for Concurrent Access to Shared Objects. In GMEM, editor, Actes des journées d’informatique musicale jim2002, marseille, pages 143–150. 2002. - [micronddr]
Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003. - [mytls]
Drepper, Ulrich. ELF Handling For Thread-Local Storage. Technical report, Red Hat, Inc., 2003. - [nonselsec]
Drepper, Ulrich. Security Enhancements in Red Hat Enterprise Linux. , 2004. - [oooreorder]
McNamara, Caolán. Controlling symbol ordering. http://blogs.linux.ie/caolan/2007/04/24/controlling-symbol-ordering/, 2007. - [sramwiki]
Wikipedia. Static random access memory. http://en.wikipedia.org/wiki/Static_Random_Access_Memory, 2006. - [transactmem]
Herlihy, Maurice and J. Eliot B. Moss. Transactional memory: Architectural support for lock-free data structures. Proceedings of 20th international symposium on computer architecture. 1993. - [vectorops]
Gebis, Joe and David Patterson. Embracing and Extending 20th-Century Instruction Set Architectures. Computer, 40(4):68–75, 2007.