C语言中的对齐问题
C语言中的对齐问题。
前言
在C语言中对齐问题主要是结构体的对齐和联合体的对齐。这篇文章主要记载结构体的对齐问题
Intel的IA32架构的处理器则不管数据是否对齐都能正确工作,但是如果想提升性能,应该注意内存对齐方式。ANSI C标准并没有规定相邻声明的变量在内存中一定要相邻。为了程序的高效性,内存对齐问题由编译器自行灵活处理,这样会导致相邻的变量之间有一些填充字节。对于基本数据类型(如int、char等),它们占用的内存空间在一个确定硬件系统下有确定的值。
ANSI C规定一种结构类型的大小是它所有字段的大小及字段之间或字段尾部的填充区大小之和。(填充区就是为了使结构体字段满足内存对齐要求而额外分配给结构体的空间)。
关于一个Linux内核中的宏,这个宏可以查看结构体中成员的偏移值。
1 | |
内存对齐的必要性
内存对齐作为一种强制要求,一方面简化了处理器与内存之间传输系统的设计,另一方面可以提升读取数据的速度。各个硬件平台在对存储空间的处理上有很大的不同。
一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如,有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。比如说arm平台
其他平台可能没有这种情况,但是最常见的情况是:如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如在32位CPU上,一般要求变量地址都是基于4位的,这样可以保证CPU用一次的读写周期就可以读取变量。如果不按4位对齐,如果变量刚好跨4位编码,这样就需要CPU用两次读写周期。
很显然,这样的效率自然低下。由此也可以简单看出,内存字节对齐是一种典型的“以空间换时间的策略”,在现代计算机拥有较大内存的情况下,这个策略是相当成功的。
结构体对齐
实际上,许多计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的起始地址的值是某个数k的倍数,这就是所谓的内存对齐,而这个k被称为该数据类型的对齐模数(alignment modulus)。
对于这个结构体的对齐来说,需要特别注意的是结构体的第一个成员开始的相对地址是 0 ,而不是 1 。
计算结构体的对齐的步骤如下:
- 将结构体内所有数据成员的长度值相加,记为sum_a。
- 将各数据成员内存对齐,按各自对齐模数而填充的字节数累加到和sum_a上,记为sum_b。对齐模数是#pragma pack指定的数值及该数据成员自身长度中数值较小者。该数据相对起始位置应该是对齐模数的整数倍。
- 将和sum_b向结构体模数对齐,该模数是#pragma pack指定的数值和结构体内部最大的基本数据类型成员长度中数值较小者,结构体的长度应该是该模数的整数倍。
使用一个例子来说明:
1 | |
根据上面的步骤:
对于结构体B而言:
- 结构体内所有数据成员的长度值相加为:sum_a=4(int为4个字节的长度)+1(char为1个字节的长度)+8(double为8个字节的长度)+4(int为4个字节的长度)+1(char为1个字节的长度)=18。
- 数据成员d为了内存对齐,根据“结构体大小的计算方法和步骤”中第2条原则,其对齐模数是8,所以之前需填充3个字节。这时候sum_b=sum_a+3=21。
- 按照定义,结构体对齐模数是结构体内部最大数据成员长度和pragma pack中较小者,而这里前者和后者都为8,因此结构体对齐模数是8。sum_b应该是8的整数倍,所以要在结构体后填充3×8-21=3个字节。
内存空间如图所示:

编写如下程序验证:
1 | |
输出如下:

需要注意的是这个输出和不同的系统有关,上面的输出系统是Red Hat Enterprise Linux 6(i386)/GCC 4.4.4
使用指令#pragma pack
除上面默认的内存对齐之外,我们也可以通过下面的方法改变默认的对齐模数。
使用伪指令#pragma pack(n),n表示对齐模数,它可以是1、2、4、8等,编译器将按照n个字节对齐。
使用伪指令#pragma pack(),取消自定义字节对齐方式,即将上一次#pragma pack(n)的设置取消,恢复为默认值。
1 | |
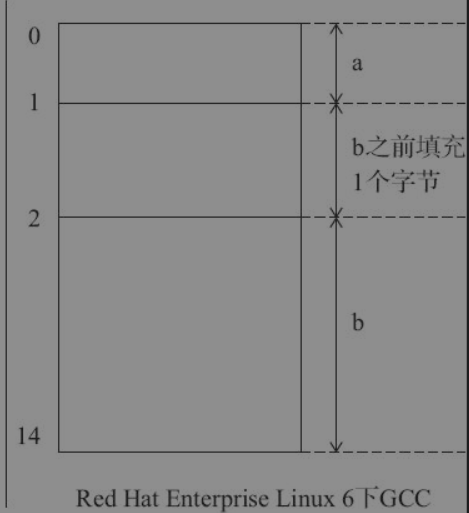
- 结构体内所有数据成员的长度值相加为:sum_a=1(char为1个字节的长度)+8(long double为8个字节的长度)=9。
- 将数据成员a放在相对偏移0处,之前不需要填充字节。数据成员b为了内存对齐,根据“结构体大小的计算方法和步骤”中第2条原则,其对齐模数是2,所以之前需要填充1个字节。这时候sum_b=sum_a+1=10。
- 按照定义,结构体对齐模数是结构体内部最大数据成员长度和pragma pack中较小者,而这里前者为8,后者为2,所以结构体对齐模数是2。sum_b是2的5倍,因此不需要再次对齐。
特殊的,可以使用#pragma pack(1)来使得系统不进行结构体对齐
1 | |
上面的结构体的大小为17,在gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04)上的输出
如果没有这些预处理语句则结果为32
位域
C语言提供了一个称之为位域语法,实际上就是可以结构体中的成员直接按照bit来存储,而不是按照byte来存储。
注意:
- 位域只可以对于整数类型使用
1 | |
结构体的布局如下:

从上面这个图可以知道位域的含义。
参考资料
- 《编写高质量代码——改善C、C++程序的151个建议》