关于Lex和Yacc
关于Lex和Yacc知识点总结
前置知识
我们知道编译器有一下的执行步骤:
词法分析、语法分析、语义分析、IR(中间代码,intermediate Representation)产生、IR优化、代码产生、最终优化。
实际上就是
词法分析->语义分析->生成中间代码->代码生成
词法分析的核心是识别源代码,将其划分为一个个的token。lex就是这样一套框架,由用户提供规则,然后lex按照这个规则对文本进行分析。然后输出以C语言编写的词法分析器源代码。
Yacc的作用是生成一个语义解析器,其可以在没有分析器时使用,但是,完整的语法分析通常需要外部词法分析器首先执行标记化阶段(单词分析),然后才是解析阶段。
所以Yacc一般和Lex一同使用。
Lex语法
Lex的语法主要包括三部分:
1 | |
其中只有规则是必须的,其他的两个段都是可选的。
定义段
定义段主要包括的是:
- C代码定义
- 指令定义
- 命令正则表达式定义
C代码定义的格式
1 | |
在 %{ 和 %} 之间定义 C 代码,lex 会将这些代码直接拷贝至输出文件中。一般会在这里定义变量,include 语句等。
指令定义
指令定义则是通过 lex 提供的一系列以%开头的指令来修改内置变量的默认值。比如:
1 | |
命名正则表达式的格式
命名正则表达式定义为一系列命名的正则表达式,用于描述不同的标识符,如:function、let、import,其基本格式如下所示:
1 | |
注意name和expression之间需要用空格隔开
实例:
1 | |
规则段
规则部分定义了一系列的 词法翻译规则(Lexical Translation Rules),每一条词法翻译规则可以分为两部分:模式 和 动作。
模式:用于描述词法规则的正则表达式
动作:模式匹配时要执行的 C 代码
词法翻译规则的基本格式如下所示:
1 | |
当词法翻译规则的模式匹配成功时,lex 默认会将匹配的 token 值存储在 yytext 变量,将匹配的 token 长度存储在 yyleng 变量。
状态
如果词法翻译规则的模式的匹配依赖上下文,那么我们可以有不同的方式来处理。我们可以根据其所依赖上下文的相对位置,分为:左状态(Left State) 和 右状态(Right State)两种。
左状态
左状态的基本格式如下所示:
<STATE>(pattern) { action; BEGIN OTHERSTATE; }
其中 STATE 为定义部分的状态定义所定义的状态,使用 %s STATE 进行定义。
右状态
右状态的基本格式如下所示:
pattern/context {action}
当匹配到 pattern 时,且紧随其后是 context,那么才算匹配成功。在这种情况下,/ 后面的内容仍然位于输入流中,它们可以作为下一个匹配的输入。
示例:
1 | |
代码段
首先看一个例子,其实现了输出文本的字符数、单词数、行数。test.l
1 | |
我们看到这个程序被分为了三段,其中第一段是全局变量的定义,第二段是规则段(如何处理文本),第三段是c代码段。
如何编译
编写了test.l文件后我们使用:
1 | |
Lex自定义的变量
Lex 变量
| yyin | FILE* 类型。 它指向 lexer 正在解析的当前文件。 |
|---|---|
| yyout | FILE* 类型。 它指向记录 lexer 输出的位置。 缺省情况下,yyin 和 yyout 都指向标准输入和输出。 |
| yytext | 匹配模式的文本存储在这一变量中(char*)。 |
| yyleng | 给出匹配模式的长度。 |
| yylineno | 提供当前的行数信息。 (lexer不一定支持。) |
Lex 函数
| yylex() | 这一函数开始分析。 它由 Lex 自动生成。 |
|---|---|
| yywrap() | 这一函数在文件(或输入)的末尾调用。 如果函数的返回值是1,就停止解析。 因此它可以用来解析多个文件。 代码可以写在第三段,这就能够解析多个文件。 方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。 最后,yywrap() 可以返回 1 来表示解析的结束。 |
| yyless(int n) | 这一函数可以用来送回除了前�n? 个字符外的所有读出标记。 |
| yymore() | 这一函数告诉 Lexer 将下一个标记附加到当前标记后。 |

正则表达式
| 字符 | 含义 |
|---|---|
| A-Z, 0-9, a-z | 构成了部分模式的字符和数字。 |
| . | 匹配任意字符,除了 \n。 |
| - | 用来指定范围。例如:A-Z 指从 A 到 Z 之间的所有字符。 |
| [ ] | 一个字符集合。匹配括号内的 任意 字符。如果第一个字符是 ^ 那么它表示否定模式。例如: [abC] 匹配 a, b, 和 C中的任何一个。 |
| * | 匹配 0个或者多个上述的模式。 |
| + | 匹配 1个或者多个上述模式。 |
| ? | 匹配 0个或1个上述模式。 |
| $ | 作为模式的最后一个字符匹配一行的结尾。 |
| { } | 指出一个模式可能出现的次数。 例如: A{1,3} 表示 A 可能出现1次或3次。 |
| \ | 用来转义元字符。同样用来覆盖字符在此表中定义的特殊意义,只取字符的本意。 |
| ^ | 否定。除开 |
| | | 表达式间的逻辑或。 |
| “<一些符号>” | 字符的字面含义。元字符具有。 |
| / | 向前匹配。如果在匹配的模版中的“/”后跟有后续表达式,只匹配模版中“/”前 面的部分。如:如果输入 A01,那么在模版 A0/1 中的 A0 是匹配的。 |
| ( ) | 将一系列常规表达式分组。 |
方括号中只保留两个操作,连字号( “-” )和抑扬号( “^” )。当把连
字号用于两个字符中间时,表示字符的范围。当把抑扬号用在开始位置时,表示对后面的表达式取 反。如果两个范式匹配相同的字符串,就会使用匹配长度最长的范式。如果两者匹配的长度相同, 就会选用第一个列出的范式。

举例
| 常规表达式 | 含义 |
|---|---|
| joke[rs] | 匹配 jokes 或 joker。 |
| A{1,2}shis+ | 匹配 AAshis, Ashis, AAshi, Ashi。 |
| (A[b-e])+ | 匹配在 A 出现位置后跟随的从 b 到 e 的所有字符中的 0 个或 1个。 |
标记申明举例
| 标记 | 相关表达式 | 含义 |
|---|---|---|
| 数字(number) | ([0-9])+ | 1个或多个数字 |
| 字符(chars) | [A-Za-z] | 任意字符 |
| 空格(blank) | “ “ | 一个空格 |
| 字(word) | (chars)+ | 1个或多个 chars |
| 变量(variable) | (字符)+(数字)*(字符)*(数字)* |
参考资料
https://www2.cs.arizona.edu/~debray/Teaching/CSc453/DOCS/tutorial-large.pdf
http://chuquan.me/2022/06/22/compiler-principle-tool-lex/
YACC
词法分析器生成器 lex,现在我们来介绍语法/语义分析器生成器 yacc。
在编译流程中,词法分析器会扫描代码文件,并将其 token 化。语法/语义分析器则会扫描 token 化后的内容,从而建立语法树,生成语义信息。
下面,我们简单介绍一下 yacc 的工作原理和基本用法。
工作原理
lex 和 yacc 分别使用各自的描述文件生成词法分析器 yylex() 和语法/语义分析器 yyparse()。
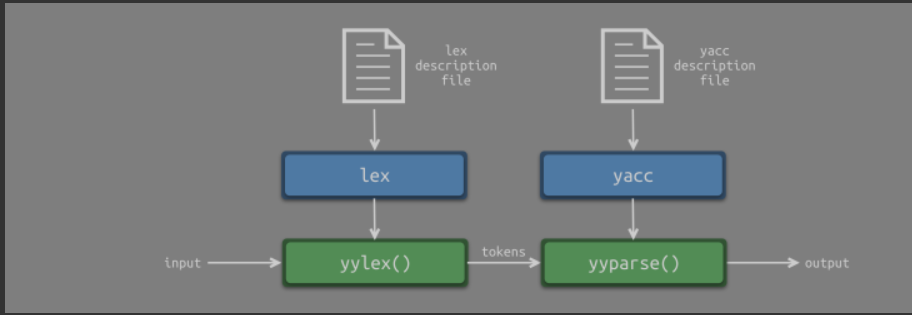
yyparse() 自身并不进行词法分析,而是调用 yylex() 进行词法分析。yylex() 返回一个 token 号,表示 token 的类型。token 值则存储在 yylval 变量中。比如:token 的类型为 算术运算符,token 的值为 +。yyparse() 则通过读取 yylex() 的返回值以及 yylval 变量分别获取 token 类型和 token 值。
yyparse() 函数的返回值有两种:
当返回值为 0 时,表示解析正确
当返回值为 1 时,表示解析错误
描述文件
yacc的描述文件的基本格式和lex一致:
1 | |
除开规则是必须要的,其他两个都是可选的.
定义
定义部分也是被分为了三部分:
- token定义
- 优先级和关联性定义
- 变量和函数定义:方便后面的语法分析