正则表达式学习
正则表达式学习笔记
概述
正则表达式是普通字符和特殊字符的合集。其具体的载体命令有:awk sed grep。系统自带的所有大的文本过滤工具在某种模式下都支持正则表达式的使用,并且还包括一些扩展的元字符集。
基础
基本组成

例子


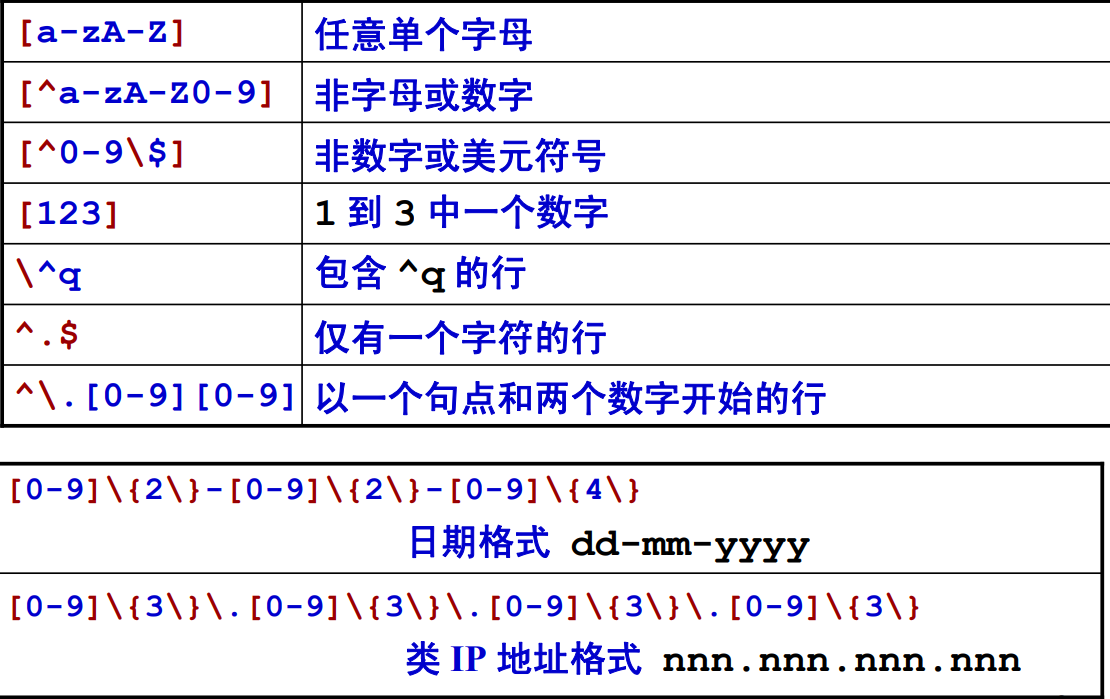
sed命令
不会改变原来的字符串。
grep命令
格式
1 | |
常用的选项
1 | |
例子
关于某个字符连续出现次数的匹配
1 | |
grep搜索文件夹
1 | |
其他例子

sed命令
概述
sed命令是一个流处理命令,其不会改变文本的文件内容。
sed的工作原理
sed 逐行处理文件(或输入),并将输出结果发送到屏幕。即:sed 从输入(可以是文件或其它标准输入)中读取一行,将之拷贝到一个编辑缓冲区,按指定的 sed 编辑命令进行处理,编辑完后将其发送到屏幕上,然后把这行从编辑缓冲区中删除,读取下面一行。重复此过程直到全部处理结束。
格式
1 | |
常用选项
1 | |
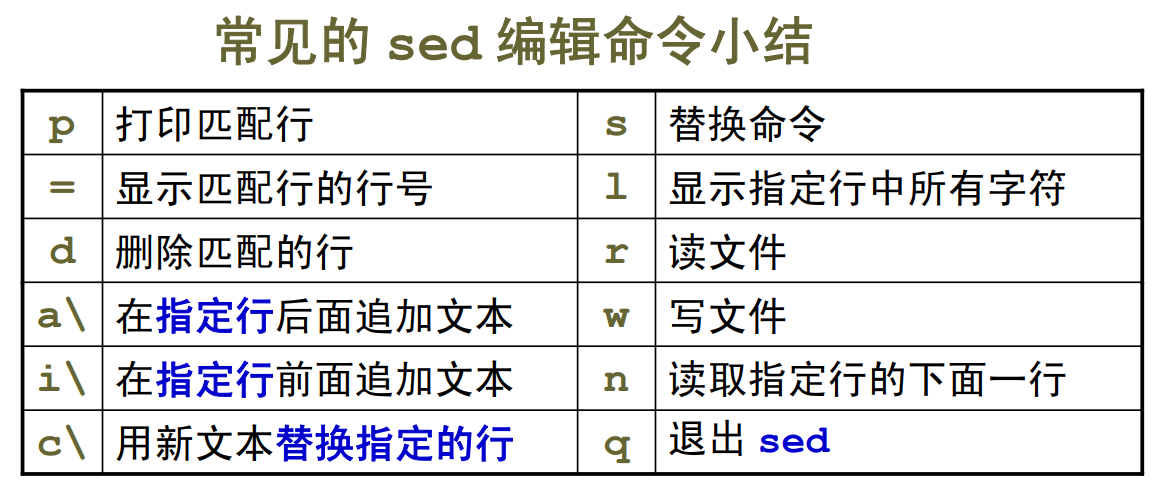
常用的sed命令
参考资料
https://math.ecnu.edu.cn/~jypan/Teaching/Linux/Linux08/lect14_Review.pdf
正则表达式学习
https://ysc2.github.io/ysc2.github.io/2023/12/09/正则表达式学习/