GDB常用命令
如何使用GDB进行调试
GCC概述
GNU 编译器套件(GCC,_GNU Compiler Collection_)最初的目标是作为一款 GNU 操作系统的通用编译器,包含有 C、C++、Objective-C、Objective-C++、Fortran、Ada、Go、BRIG(HSAIL)等语言的前端及其相关的libstdc++、libgcj等库,目前已经移植到 Windows、Mac OS X 等商业化操作系统。GCC 编译器套件当中包含了诸多的软件包,主要的软件包如下面表格所示:
| 名称 | 描述 |
|---|---|
| cpp | C 预处理器。 |
| gcc | C 编译器。 |
| g++ | C++ 编译器。 |
| gccbug | 用于创建 BUG 报告的 Shell 脚本。 |
| gcov | 覆盖测试工具,用于分析程序需要优化的位置。 |
| libgcc | GCC 运行库。 |
| libstdc++ | 标准 C++库。 |
| libsupc++ | C++语言支持函数库。 |
Ubuntu、Mint 等使用 deb 格式软件包的 Linux 发行版通常会默认安装 GCC 编译器,但是由于相关的软件包可能并不完整,因此可以通过如下命令安装完整的 GCC 编译环境。
文件分析指令
1 | |
一、信息显示
1、显示gdb版本 (gdb) show version
2、显示gdb版权 (gdb) show version or show warranty
3、启动时不显示提示信息gdb -q exe 或者.bashrc 添加alias gdb=”gdb -q”,重启shell
4、退出时不显示提示信息(gdb) set confirm off
5、输出信息多时不会暂停输出(gdb)set pagination off
基本命令
1 | |
二、函数
1、列出函数的名字(gdb) info functions
2、是否进入待调试信息的函数(gdb)step s
3、进入不带调试信息的函数(gdb)set step-mode on
4、退出正在调试的函数(gdb)return expression 或者 (gdb)finish
5、直接执行函数(gdb)start 函数名 call函数名
6、打印函数堆栈帧信息(gdb)info frame or i frame
7、查看函数寄存器信息(gdb)i registers
8、查看函数反汇编代码(gdb)disassemble func
1 | |
9、打印尾调用堆栈帧信息(gdb)set debug entry-values 1
10、选择函数堆栈帧(gdb)frame n
11、向上或向下切换函数堆栈帧(gdb)up n down n
三、断点
1、在匿名空间设置断点(gdb)b Foo::foo (gdb) b (anonymous namespace)::bar
2、在程序地址上打断点(gdb)b address (gdb) b 0x400522
3、在程序入口处打断点stripa.out
readelf -h a.out或者(gdb)info files定位Entry point: 0x400440 (gdb)b *0x400440
4、在文件行号上打断点(gdb)b linenum (gdb)b file.cpp:linenum (gdb)info breakpoints
5、保存已经设置的断点(gdb)save breakpoints file-breakpoints-to-save (gdb)source file-breakpoints-to-save
6、设置临时断点(gdb)tbreak linenum
7、设置条件断点(gdb)b linenum if cond b 11 if i==10
8、忽略断点(gdb)ignore bnum count
9、反向步进程序,直到到达另一个源码行的开头。
reverse-step [N] 参数 N 表示执行 N 次(或由于另一个原因直到程序停止)。
10、reverse-next
反向步进程序,执行完子程序调用。
reverse-next [N]
如果要执行的源代码行调用子程序,则此命令不会进入子程序,调用被视为一个指令。
四、观察点
1、设置观察点(gdb)watch a wacth (type)adress info watchpoints disable、enable、delete
2、设置观察点只针对特定线程生效(gdb)info threads watch expr thread threadnum wa a thread 2
3、设置读观察点(gdb)rwatch
4、设置读写观察点(gdb)awacth
五、Catchpoint
1、让catchpoint只触发一次(gdb)tcatch
2、为fork调用设置catchpoint (gdb)catch fork
3、为vfork调用设置catchpoint (gdb)catch vfork
4、为exec调用设置catchpoint (gdb)catch exec
5、为系统调用设置catchpoint (gdb)catch syscall name or num
6、通过ptrace调用设置catchpoint破解anti-debugging的程序 (gdb)catch syscall ptrace set $rax=0
八、core dump文件
1、为调试进程产生core dump文件(gdb)generate-core-file or gcore
2、加载可执行程序和core dump文件(gdb)gdb -q /data/nan/a /var/core/core.a.22268.1402638140
九、汇编
1、设置汇编指令格式(gdb)set disassembly-flavor intel disassemble main
2、在函数的第一条汇编指令打断点(gdb)b *main
3、自动反汇编后面要执行的代码(gdb)set disassemble-next-line on
set disassemble-next-line auto set disassemble-next-line off
4、将源程序和汇编指令映射起来(gdb)disas /m main
5、显示将要执行的汇编指令(gdb)display /i $pc
6、打印寄存器的值(gdb)i registers i all-registers i registers eax
7、显示程序原始机器码(gdb)disassemble /r main
十、改变程序执行顺序
1、改变字符串的值(gdb)set main::p1=”Jil”
2、设置变量的值(gdb)set var variable=expr set var i = 8 set {int}0x8047a54 = 8 set var eax=83、修改PC寄存器的值(gdb)p
pc set var $pc=0x08050949
4、跳转到指定位置执行(gdb)j 15
5、使用断点命令改变程序的执行
1 | |
6、修改被调试程序的二进制文件gdb -write ./a.out (gdb)show write set write on disassemble /mr drawing set variable (short)0x400651=0x0ceb disassemble /mr drawing
十一、信号
1、查看信号处理信息(gdb)i signals
2、信号发生时是否暂停程序(gdb) handle signal stop/nostop
3、信号发生时是否打印信号信息(gdb)handle signal print/noprint
4、信号发生时是否把信息丢给程序处理(gdb)handle signal pass(noignore)/nopass(ignore)
5、给程序发送信息(gdb)signal signal_name
6、使用”siginfo”变量(gdb)ptype
_siginfo
十二、共享库
1、显示共享连接库信息(gdb)info sharedlibrary regex
十三、脚本
1、配置gdb init文件(gdb) home目录下的 .gdbinit
2、按何种方式解析脚本文件(gdb)set script-extension off soft strict
3、保存历史命令(gdb)set history filename ~/.gdb_history set
history save on
十四、源文件
1、设置源文件查找路径(gdb)directory ../ki/
2、替换查找源文件的目录(gdb)set substitute-path from to
十五、图形化界面
1、进入和退出图形化调试界面(gdb)gdb -tui program
2、显示汇编代码窗口(gdb)layout asm
3、显示寄存器窗口(gdb)layout regs
4、调整窗口大小(gdb)winheight [+ | -]count
十六、其它
1、命令行选项的格式(gdb)gdb -help
2、支持预处理器宏信息(gdb)gcc -g3
3、使用命令的缩写形式(gdb)b -> break
1 | |
4、在gdb中执行shell命令和make(gdb)shell ls
5、在gdb中执行cd和pwd命令(gdb)pwd cd tmp
6、设置命令提示符(gdb)gdb -q `which gdb
7、设置被调试程序的参数(gdb)gdb -args ./a.out a b c set args a b c r a b
8、设置被调试程序的环境变量(gdb)set env varname=value
9、得到命令的帮助信息(gdb)help
10、记录执行gdb的过程(gdb)set logging file log.txt set logging on
查询运行信息
where/bt :当前运行的堆栈列表;
bt backtrace 显示当前调用堆栈
up/down 改变堆栈显示的深度
set args 参数:指定运行时的参数
show args:查看设置好的参数
info program: 来查看程序的是否在运行,进程号,被暂停的原因。
分割窗口
layout:用于分割窗口,可以一边查看代码,一边测试:
layout src:显示源代码窗口
layout asm:显示反汇编窗口
layout regs:显示源代码/反汇编和CPU寄存器窗口
layout split:显示源代码和反汇编窗口
Ctrl + x,再按1:单窗口模式,显示一个窗口
Ctrl + x,再按2:双窗口模式,显示两个窗口
Ctrl + x,再按a:回到传统模式,即退出layout,回到执行layout之前的调试窗口。
Ctrl + L:刷新窗口,每当窗口显示不正常的时候都可以使用此组合键刷新。
关于反向执行程序
其实在gdb中是可以反向执行程序的, 使用命令record或者是record btrace开启支持.开启后相关的命令如下:
1 | |
这个命令和step一样, 只是执行的方向相反, 这个是向后执行直到达到了不同源代码的开头, 其实
这个命令和上一个一样就是si命令的反方向版本
1 | |
这个命令就是next和nexti的反向版本
1 | |
finish的反向版本,正如 finish 命令将您带到当前函数返回的位置, reverse-finish 将您带到调用它的位置
修改目标的二进制文件
在默认情况下gdb是以只读模式打开目标文件的,但是可以通过一下命令开启写权限
1 | |
下面通过一个例子来说明使用方法:
这是程序的反汇编码
1 | |
现在我们修改程序的二进制码:
1 | |
重新查看反汇编码:
1 | |
可以看到 0x0000000000400668 <+27>: eb 0a jmp 0x400674 <drawing+39>变成了jmp从je.
源文件的查找
gdb热补丁
在调试大型程序时, 我们无法保证自己一次性找到了程序所有debug. 但是大型程序的编译、部署都需要耗费大量的时间, 所以gdb通过热补丁来弥补这一缺陷.
常用命令
- 获取函数的返回值的方法:
1 | |
查看连续内存的方式:
1
2
3# 可以使用GDB的"@"操作符查看连续内存,"@"的左边是第一个内存的地址的值,"@"的右边则你你想查看内存的长度。先要查看int arr[] = {2, 4, 6, 8, 10}
p *arr@3 #查看3个成员查看函数参数、变量的值
1
2
3
4info args #查看参数的值
info locals #查看函数中所有的变量的值举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
int func(int num){
if(num==1){
return 1;
}else{
return num*func(num-1);
}
}
int main ()
{
int n = 5;
int result = func(n);
printf("%d! = %d",n,result);
return 0;
}
调试这个程序
1 | |
- GDB中的help命令,注意直接使用help命令显示的是,GDB中的类:
1
2
3
4
5
6
7
8
9aliases -- User-defined aliases of other commands.
breakpoints -- Making program stop at certain points.
data -- Examining data.
files -- Specifying and examining files.
internals -- Maintenance commands.
obscure -- Obscure features.
running -- Running the program.
stack -- Examining the stack.
status -- Status inquiries.
我们需要使用help class命令来查看这个类的详细信息。
print命令和display命令的关系:
首先print这个命令的作用是显示、修改对象的值。但是dispaly只可以显示对象的值,而不可以更改值。不过这个显示值是可以一直显示的。
具体的:print命令:
1 | |
调试这个程序:
1 | |
display命令:
仍然使用上面的程序调试:
1 | |
事实上,对于使用 display 命令查看的目标变量或表达式,都会被记录在一张列表(称为自动显示列表)中。使用info display可以查看所有displau的对象:
1 | |
其中,各列的含义为:
Num 列为各变量或表达式的编号,GDB 调试器为每个变量或表达式都分配有唯一的编号;
Enb 列表示当前各个变量(表达式)是处于激活状态还是禁用状态,如果处于激活状态(用 y 表示),则每次程序停止执行,该变量的值都会被打印出来;反之,如果处于禁用状态(用 n 表示),则该变量(表达式)的值不会被打印。
Expression 列:表示查看的变量或表达式。
取消显示有两个命令:undispaly delete:
1 | |
info和set&unset跟show之间的关系
info 查看程序状态信息。例如断点、寄存器、线程、局部变量等
1 | |
show 查看 gdb 配置信息。与 info 不同, show 查看 GDB 本身的配置信息
1 | |
set 设置变量值。有时指定变量类型才能设置,如 set *(int*)(&a) = 3,还可以配置程序的环境如:环境变脸、参数。
1 | |
线程切换命令:
1
thread n #将线程切换为n号线程发送信号的命令:
1
2signal 9 #发送信号9
signal SIGKILL #发送直接杀死信号whatis命令和ptype命令之间的关系:
首先需要明确的是,这两个命令都是查看对象的类型的命令,只是ptype相当于whatis命令更加详细,会给出结构体的定义,而whatis不会。其他都一致。直接退出当前函数不执行剩下的代码:
1
returndisable命令和enable命令;1
2
3
4
5
6
7
8
9
10
11
12disable 1 2 关闭断点1 2
enable 1 打开断点1
上面都是需要断点号,通过info breakpoint
info break 来查看断点的相关信息
关于enable命令:
enable [breakpoints] [num...] 激活用 num... 参数指定的多个断点,如果不设定 num...,表示激活所有禁用的断点
enable [breakpoints] once num… 临时激活以 num... 为编号的多个断点,但断点只能使用 1 次,之后会自动回到禁用状态
enable [breakpoints] count num... 临时激活以 num... 为编号的多个断点,断点可以使用 count 次,之后进入禁用状态
enable [breakpoints] delete num… 激活 num.. 为编号的多个断点,但断点只能使用 1 次,之后会被永久删除。信号的处理配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23使用info signal SIGINT
Signal Stop Print Pass to program Description
SIGINT Yes Yes No Interrupt
以上各列的含义是:
Signal:各个信号的名称;
Stop:当信号发生时,是否终止程序执行。Yes 表示终止,No 表示当信号发生时程序认可继续执行;
Print:当信号发生时,是否要求 GDB 打印出一条提示信息。Yes 表示打印,No 表示不打印;
Pass:当信号发生时,该信号是否对程序可见。Yes 表示程序可以捕捉到该信息,No 表示程序不会捕捉到该信息;
Description:对信号所表示含义的简单描述。
使用下面的命令配置:
handle signal mode
mode是:
nostop:当信号发生时,GDB 不会暂停程序,其可以继续执行,但会打印出一条提示信息,告诉我们信号已经发生;
stop:当信号发生时,GDB 会暂停程序执行。
noprint:当信号发生时,GDB 不会打印出任何提示信息;
print:当信号发生时,GDB 会打印出必要的提示信息;
nopass(或者 ignore):GDB 捕获目标信号的同时,不允许程序自行处理该信号;
pass(或者 noignore):GDB 调试在捕获目标信号的同时,也允许程序自动处理该信号。edit命令
这个命令可以允许在GDB中修改程序的源代码,但是非常不好用,我也不会用。search命令
搜索命令,可以快速搜索函数名1
2
3
4
5search <regexp>
reverse-search <regexp>
第一项命令格式表示从当前行的开始向前搜索,后一项表示从当前行开始向后搜索。其中 regexp 就是正则表达式,正则表达式描述了一种字符串匹配的模式,可以用来检查一个串中是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串。很多的编程语言都支持使用正则表达式。GDB窗口命令
使用命令:layout 打开gdb的图形化窗口,help layout快速查看选项
- 窗口大小的改变
1
2
3
4
5
6
7
8
9
10
11#将代码窗口的高度扩大 5 行代码
winheight src + 5
#将代码窗口的高度减小 4 代码
winheight src - 4
ctrl l #刷新窗口
Ctrl + L:刷新窗口
Ctrl + x,再按1:单窗口模式,显示一个窗口
Ctrl + x,再按2:双窗口模式,显示两个窗口
Ctrl + x,再按a:回到传统模式,即退出layout,回到执行layout之前的调试窗口。 - 窗口焦点切换
在默认设置下,方向键和 PageUp/PageDown 都是用来控制 GDB TUI 的 src 窗口的,所以如果想要使用方向键控制输入的命令,就必须先focus cmd
显示前一条命令和后一条命令的功能:Ctrl + N/Ctrl + P
注意:通过方向键调整了GDB TUI 的 src 窗口以后,可以用 update 命令重新把焦点定位到当前执行的代码上。
focus 命令调整焦点位置
默认情况下焦点是在 src 窗口,通过 focus next 命令可以把焦点移到 cmd 窗口,这时候就可以像以前一样,通过方向键来切换上一条命令和下一条命令。
使用 focus prev 切回到源码窗口,如果焦点不在 src 窗口,我们就不必使用方向键来浏览源码了。
attach命令1
2
3
4等效于-p gdb -p 1111 使用于还没进入gdb之前
不同的是
attach 1111 是使用于进入了gdbgdb调试指定源代码、调试符号
1
2
3
4
5
6#gdb指定具有调试符号的库
show debug-file-directory #可以查看调试库的默认位置,默认就是/usr/lib/debug/
set debug-file-directory /usr/lib/debug/
#指定源代码目录
directory /home/ysc/open_sources_code/glibc-2.35 #其中directory可以简写为dirgdb调试如何查看#define
1 | |
注意以
i结尾的命令并不是打断点,单汇编指令执行如:nextistarti查看内存上的值:
常使用这个命令查看栈空间。
特别需要注意的是在小端序上,显示的值是需要从右往左读:0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
需要右往左读:0x00 00 55 55 55 55 90 a0
需要注意的一件事是,这里堆地址以 0x5555 开头,栈地址以 0x7fffff 开头。 所以很容易区分栈上的地址和堆上的地址之间的区别。
1 | |
F:格式
u:显示为无符号十进制数
o:显示为八进制数
t:two 显示为二进制数
a:地址
c:显示为ascii
f:浮点数
s:显示为字符串
i:显示机械语言
x:十六进制
U:单位
b:字节
h:半字(两个字节)
w:字(四字节)
g:双字
特殊用法:
1 | |
注意点
- 如果
x $rsi报错:Cannot access memory at address xxx则说明这个寄存器中存储的不是地址而是一个值, 此时使用p $rsi即可.
生成内存转储
1
2
3generate-core-file
#或
gcore命令可以直接从命令行生成内核转储文件查看gdb的历史操作以及输出
1
2set trace-commands on
set logging on此时再在gdb中运行命令,会在启动gdb时所在路径处建立
gdb.txt文件。
1 | |
Tips : 在gdb.txt中,调试命令前的 (gdb)提示符变成了+,使得命令与输出更加难以区分。 可以执行命令,使得+号高亮
1 | |
此命令使+号变为红色,若需要改成其他颜色,可查看man console_codes
如何快速查看程序的退出原因
- 直接执行
c info program这个指令可以直接查看程序退出的原因- 使用
info stack查看退出函数的调用栈 - 使用
info registers查看退出时寄存器中的值
- 直接执行
改善gdb的输出的设置
1
2
3set print object on: 当打印指向对象的指针时,显示其真实类型
set print array on: 用更好的格式打印数组,但是需要占用更多空间
set print pretty on: 打印结构体/类时使用缩进关于查看源代码
使用list命令或者是l来查看源代码,后面可以跟上需要查看的行号。需要注意的是在默认情况下list命令会输出10行代码,如果想要进行更改需要:1
2set listsize 20 # 将一次输出的函数更改为20行,
set listsize unlimited # 无限制其他使用方法:
1
2
3l 1,20 # 查看1到20行的代码
l 1.c:10 # 查看1.c文件的第10行附近的10行代码
l 1.c:10,1.c20 # 指定文件来查看行数我们调试的使用常常会有修改代码的需求, 其实gdb是支持不退出程序修改的. 使用命令
edit即可1
2
3
4
5
6
7
8
9edit 32 # 编辑当前文件的32行
edit main # 编辑当前文件的main函数
edit main.c:init # 编辑main.c中的init函数
edit mian.c:32 # 编辑main.c中的32行
shell gcc -g -lpthread -o 29-1 ./29-1.c # 在修改了源代码之后需要重新编译, 需要注意的是如果没有重新编译代码, 直接使用l命令查看源代码, 显示的还是没有更改过的代码.直接更改寄存器中的值
1
set var $pc=0x08050949带参数调试
1
2
3
4
5
6
7
8
9
10
11# 方法一
gdb --args a.out qq bb
# 方法二
gdb ./a.out
run qq bb
# 方法三
gdb ./a.out
set args qq bb
show args # 显示参数
编译步骤
实质上从hello.c源代码到hello或a.out可执行文件,GCC 的编译过程大致经历了下面 4 个步骤:

- 预处理:C 编译器对各种预处理命令进行处理,包括头文件包含、宏定义的扩展、条件编译的选择等(_使用
gcc -E_);
1 | ➜ gcc -E main.c -o main.i |
- 编译:对预处理得到的源代码文件进行翻译转换,产生由机器语言描述的汇编文件(_使用
gcc -S_);
1 | ➜ gcc -S main.i |
- 汇编:将汇编代码转译成为机器码(_使用
gcc -c_);
1 | ➜ gcc -c main.s |
- 链接:将机器码中的各种符号引用与定义转换为可执行文件中的相应信息(例如虚拟地址);
1 | ➜ gcc main.o -o main |
为了便于查找,下表列出了编译和链接 C/C++ 程序时各类文件扩展名的释义:
| 后缀名称 | 描述内容 |
|---|---|
.c |
C 语言源码,必须经过预处理。 |
.C、.cc、.cxx |
C++源代码,必须经过预处理。 |
.h |
C/C++语言源代码的头文件。 |
.i |
由.c文件预处理后生成。 |
.ii |
由.C、.cc、.cxx源码预处理后生成。 |
.s |
汇编语言文件,是.i文件编译后得到的中间文件。 |
.o |
目标文件,是编译过程得到的中间文件。 |
.a |
由目标文件构成的文件库,也称为静态库。 |
.so |
共享对象库,也称为动态库。 |
指定编译规范
由于 GCC 同时支持多套 C 程序语言规范,因而编译时可以通过选项指定当前需要遵循的语言规范,具体请参考下表:
| 规范 | 规范 | 选项 | 补充 |
|---|---|---|---|
| C89 / C90 | ANSI C (X3.159-1989) 或 ISO/IEC 9899:1990 | -std=c90 |
-std=iso9899:1990、-ansi |
| C94 / C95 | 95 年发布的 C89/C90 修正版,此次修正通常称作 AMD1 | - | -std=iso9899:199409 |
| C99 | ISO/IEC 9899:1999 | -std=c99 |
-std=iso9899:1999 |
| C11 | ISO/IEC 9899:2011 | -std=c11 |
-std=iso9899:2011 |
| GNU C89 / C90 | 带 GNU 扩展的 C89/C90 | -std=gnu90 |
- |
| GNU C99 | 带 GNU 扩展的 C99 | -std=gnu99 |
- |
| GNU C11 | 带 GNU 扩展的 C11 | -std=gnu11 |
- |
例如下面代码当中,指定了 GCC 的编译过程遵循 C89/C90 规范,结果编译时提示错误信息:C++ style comments are not allowed in ISO C90。
1 | ➜ gcc main.c -std=c90 |
缺省情况下,GCC 默认使用的是
-std=gnu11规范,即携带 GNU 扩展的 C11 标准。
参数选择
-symbols <file>
-s <file>
从指定文件中读取符号表。
-se file
从指定文件中读取符号表信息,并把他用在可执行文件中。
-core <file>
-c <file>
调试时core dump的core文件。
-directory <directory>
-d <directory>
加入一个源文件的搜索路径。默认搜索路径是环境变量中PATH所定义的路径。
多线程调试
GDB 是支持多线程调试的,下面我们通过一个例子来展示如何使用 GDB 进行调试。
本文档主要参看«Debugging with GDB» Tenth Edition, for gdb version 8.0.1,本节我们主要讲述一下使用GDB来调试多线程及多进程程序。
1. 调试多线程
1.1 概念介绍
在有一些操作系统上,比如GNU/Linux与Solaris,一个进程可以有多个执行线程。线程的精确语义因操作系统不同而有一些区别,但一般来说一个程序的线程类似与多进程,除了多线程是共享同一个地址空间之外。另一方面,每一个线程都有其自己的寄存器(registers)和执行栈(execution stack),并可能拥有其自己的私有内存。
GDB提供了如下的一些facilities来用于支持多线程的调试:
新线程的自动通知
thread thread_id: 用于在线程之间切换的命令
info threads: 用于查询当前存在的线程信息
thread apply [thread-id-list] [all] args: 对一系列的线程应用某一个命令
thread-specific breakpoints
set print thread-events: 控制是否打印线程启动、退出消息
set libthread-db-search-path path: 假如默认的选择不兼容当前程序的话,让用户选择使用那个
thread-db
上面的线程调试facility使得你可以在程序运行期间观察到所有的线程,但是无论在什么时候只要被gdb接管控制权,只会有一个线程处于focus状态。该线程被称为current thread。GDB调试命令都是以当前线程(current thread)的视角来显示程序信息。
当GDB在程序中检测到有一个新的线程,其都会打印该线程在目标系统的标识信息,格式为[New systag], 这里systag是一个线程标识,其具体的形式可能依系统不同而有些差异。例如在GNU/Linux操作系统上,当GDB检测到有一个新的线程时,你可能会看到:
1 | |
相反,在一些其他的系统上,systag可能只是一个很简单的标识,例如process 368。
用于调试目的,GDB会用其自己的线程号与每一个“线程inferior”相关联。在同一个inferior下,所有线程之间的标识号都是唯一的;但是不同inferior下,线程之间的标识号则可能不唯一。你可以通过inferior-num.thread-num语法来引用某一个inferior中的指定线程(这被称为qualified Thread ID)。例如,线程2.3引用inferior 2中线程number为2的线程。假如你省略inferior number的话,则GDB默认引用的是当前inferior中的线程。
在你创建第二个inferior之前,GDB并不会在thread IDs部分显示inferior number。
有一些命令接受以空格分割的thread ID列表作为参数,一个列表元素可以是:
1 | |
例如,假如当前的inferior是1,inferior 7有一个线程,其ID为7.1,则线程列表1 2-3 4.5 6.7-9 7.*表示inferior 1中的线程1至线程3,inferior 4中的线程5,inferior 6中的线程7至线程9, 以及inferior 7中的所有线程。
从GDB的视角来看,一个进程至少有一个线程。换句话说,GDB会为程序的主线程指定一个thread number,即使在该程序并不是多线程的情况下。参看如下:
1 | |
编译调试:
1 | |
假如GDB检测到程序是多线程的,假如某个线程在断点处暂停时,其就会打印出该线程的ID及线程的名称:
1 | |
相似的,当程序收到一个信号之后,其会打印如下的信息:
1 | |
1.2 GDB线程相关命令
- info threads [thread-id-list]: 用于显示一个或多个线程的信息。假如并未指定参数的话,则显示所有线程的信息。你可以指定想要显示的线程列表。GDB会按如下方式显示每一个线程:
1 | |
例如:
1 | |
假如当前你正在调试多个inferiors,则GDB会使用限定的inferior-num.thread-num这样的格式来显示thread IDs。否则的话,则只会显示thread-num。
这里的 inferiors 表示一个什么意思?其实就是当下 GDB 正在调试的这个程序,在GDB中,调试器本身被称为"superior",而它所控制的程序则被称为"inferior"。
假如指定了-gid选项,那么在执行info threads命令时就会显示每一个线程的global thread ID:
1 | |
- thread thread-id: 使
thread-id所指定的线程为当前线程。该命令的参数thread-id是GDB所指定的thread ID,即上面info threads命令显示的第一列。通过此命令切换之后,GDB会打印你所选中的线程的系统标识和当前的栈帧信息:
1 | |
类似于在创建线程时打印出的[New ...]这样的消息,Switching to后面的消息打印也依赖于你所使用的系统
thread apply [thread-id-list | all [-ascending]] command: 本命令允许你在一个或多个线程上应用指定的command。如果要在所有线程上按降序的方式应用某个command,那么使用 ‘thread apply all command’; 如果要在所有线程上按升序的方式应用某个command,那么使用’thread apply all -ascending command’;thread name [name]: 本命令用于为当前线程指定一个名称。假如并未指定参数的话,那么任何已存在的由用户指定的名称都将被移除。命名后线程的名称会出现在
info threads的显示信息中。thread find [regexp]: 用于查询名称或
systag匹配查询表达式的线程。例如:
1 | |
- set libthread-db-search-path [path]: 假如本变量被设置,那么GDB将会使用所设置的路径(路径目录之间以’:’分割)来查找
libthread_db。假如执行此命令时,并不指定path,那么将会被重置为默认值(在GNU/Linux及Solaris系统下默认值为$sdir:$pdir,即系统路径和当前进程所加载线程库的路径)。而在内部,默认值来自于LIBTHREAD_DB_SEARCH_PATH宏定义。
在GNU/Linux以及Solaris操作系统上,GDB使用该辅助libthread_db库来获取inferior中线程的信息。GDB会使用’libthread-db-search-path’来搜索libthread_db。假如’set auto-load libthread-db’被启用的话,GDB首先会搜索该inferior所加载的线程调试库。
1 | |
假如在上述目录中找到了libpthread_db库,那么GDB就会尝试用当前inferior process来初始化。假如初始化失败的话(一般在libpthread_db与libpthread版本不匹配的情况),GDB就会卸载该libpthread_db,然后尝试继续从下一个路径搜索libpthread_db。假如最后都没有找到适合的版本,GDB会打印相应的警告信息,接着线程调试将会被禁止。
注意: 本命令只在一些特定的平台上可用。
show libpthread-db-search-path: 用于显示当前
libpthread_db的搜索路径set debug libpthread-db / show debug libpthread-db: 用于启用或关闭
libpthread-db相关的事件信息的打印。1为启用, 0为关闭。set scheduler-locking mode: 用于设置
锁定线程的模式(scheduler locking mode)。其适用于程序正常执行、record mode以及重放模式。
1 | |
- show scheduler-locking: 用于显示当前的锁定模式
1.3 多线程调试示例
- 示例源代码
如下是我们所采用的调试示例源代码test.c:
1 | |
- 编译运行
1 | |
然后我们再通过如下命令查看主线程和两个子线程之间的关系:
1 | |
再接着通过pstack来查看线程栈结构:
1 | |
- GDB调试多线程程序
1) 启动gdb调试,并在上述代码a++处加上断点
1 | |
2) 运行并查看inferiors及threads信息
1 | |
从上面我们看到当前停在我们设置的断点处。
接着我们执行如下:
1 | |
上面我们看到当我们在单步调试pthread_run1的时候,pthread_run2也在执行。但是当我们暂停在断点处时,pthread_run2是不在执行的。
如果我们想在调试一个线程时,其他线程暂停执行,那么可以使用set scheduler-locking on来锁定。例如:
1 | |
2. 调试多进程
2.1 基本概念
在大多数系统上,GDB对于通过fork()函数创建的子进程的调试都没有专门的支持。当一个程序fork()之后,GDB会继续调试父进程,而子进程仍会畅通无阻的运行。假如你在代码的某个部分设置了断点,然后子进程执行到该位置时,则子进程会受到一个SIGTRAP信号并导致子进程退出(除非子进程catch了该信号)。
然而,假如你想要调试子进程的话,也有一种相对简单的取巧方法。就是在执行完fork之后,在进入子进程代码时调用sleep()方法。这里可以根据某个环境变量是否设置或者某个文件是否存在来决定是否进入sleep(),这样就可以使得我们在非调试状态下避免休眠。当子进程进入sleep状态时,我们就可以通过ps命令查看到子进程的进程ID。接着可以通过使用GDB并attach到该子进程,然后就可以像调试普通程序一样进行调试了。
在有一些系统上,GDB对使用fork()或vfork()函数创建的子进程的调试提供了支持。在GNU/Linux平台上,从内核2.5.46版本开始该特性就被支持。
默认情况下,当一个程序forks之后,GDB会继续调试父进程,而对子进程没有任何的影响。
假如你想要跟随子进程而不是父进程,那么可以使用set follow-fork-mode命令:
- set follow-fork-mode mode: 设置GDB调试器如何对
fork或者vfork进行响应。参数mode的取值可以为
1 | |
- show follow-fork-mode: 显示当前的跟随模式
在Linux上,假如parent进程与child进程都想要调试的话,那么可以使用set detach-on-fork命令。
- set detach-on-fork mode: 用于告诉GDB在fork()之后是否分离其中的一个进程,或者同时保持对他们的控制。mode可取值为
1 | |
- show detach-on-fork: 用于显示
detach-on-fork模式的值
假如你选择设置detach-on-fork的值为off,那么GDB将会将会保持对所有fork进程的控制(也包括内部fork)。你可以通过使用info inferiors命令来查看当前处于GDB控制之下的进程,并使用inferior命令来进行切换。
如果要退出对其中一个fork进程的调试,你可以通过使用detach inferiors命令来使得该进程独立的运行,或者通过kill inferiors命令来将该进程杀死。
假如你使用GDB来调试子进程,并且是在执行完vfork再调用exec,那么GDB会调试该新的target直到遇到第一个breakpoint。另外,假如你在orginal program的main函数中设置了断点,那么在子进程的main函数中也会保持有该断点。
在有一些系统上,当子进程是通过vfork()函数产生的,那么在完成exec调用之前,你将不能对父进程或子进程进行调试。
假如在执行完exec调用之后,你通过运行run命令,那么该新的target将会重启。如果要重启父进程的话,使用file命令并将参数设置为parent executable name。默认情况下,当一个exec执行完成之后,GDB会丢弃前一个可执行镜像的符号表。你可以通过set follow-exec-mode命令来改变这一行为:
- set follow-exec-mode mode: 当程序调用
exec之后,GDB相应的行为。exec调用会替换一个进程的镜像。mode取值可以为:
1) new: GDB会创建一个新的inferior,并将该进程重新绑定到新的inferior。在执行exec之前的所运行的程序可以通过重启原先的inferior(original inferior)来进行 重启。例如:
1 | |
- same: GDB会将exec之后的新镜像加载到同一个
inferior中,以替换原来的镜像。在执行exec之后如果要重启该inferior,那么可以通过运行run命令。这是默认模式。例如:
1 | |
2.2 调试示例
- 调试子进程
1) 示例源码
1 | |
- 调试步骤
首先执行下面的命令进行编译:
1 | |
在调试多进程程序时,GDB默认会追踪处理父进程。例如:
1 | |
上面我们看到,子进程很快就打印出了hello,world!,说明GDB并没有控制住子进程。而在父进程中,我们通过单步执行到第18行的return,然后父进程返回退出。
如果要调试子进程,要使用如下的命令: set follow-fork-mode child。例如:
1 | |
上面我们看到程序执行到第20行: 子进程打印出hello,world!.
- 同时调试父进程和子进程
1) 示例源码
1 | |
- 调试步骤
首先通过执行下面的命令执行编译:
1 | |
从前面我们知道,GDB默认情况下只会追踪父进程的运行,而子进程会独立运行,GDB不会控制。
如果同时调试父进程和子进程,可以使用set detach-on-fork off(默认值是on)命令,这样GDB就能同时调试父子进程,并且在调试一个进程时,另一个进程处于挂起状态。例如:
1 | |
上面在使用set detach-on-fork off命令之后,使用info inferiors命令查看进程状态,可以看到父进程处在被GDB调试的状态(前面显示*表示正在被调试)。当父进程退出后,用inferior infno切换到子进程去调试。
此外,如果想让父子进程同时运行,可以使用set schedule-multiple on(默认值为off)命令,仍以上述代码为例:
1 | |
可以看到打印出了Child,证明子进程也在运行了。
3. 设置用于返回的书签
在许多操作系统上,GDB能够将程序的运行状态保存为snapshot,这被称为checkpoint,后续我们就可以通过相应的命令返回到该checkpoint。
回退到一个checkpoint,会使得所有发生在该checkpoint之后的操作都会被做undo。这包括内存的修改、寄存器的修改、甚至是系统的状态(有一些限制)。事实上,类似于回到保存checkpoint的时间点。
因此,当你在单步调试程序,并且认为快接近有错误的代码点时,你就可以先保存一个checkpoint。然后,你继续进行调试,假如碰巧错过了该关键代码段,这时你就可以回退到该checkpoint并从该位置继续进行调试,而不用完全从头开始来调试整个程序。
要使用checkpoint/restart方法来进行调试的话,需要用到如下命令:
checkpoint: 将调试程序的当前执行状态保存为一个snapshot。本命令不携带任何参数,但是其实GDB内部对于每一个checkpoint都会指定一个整数ID,这有些类似于breakpoint ID.
info checkpoints: 列出当前调试session所保存的checkpoints。对于每一个checkpoint,都会有如下信息被列出
1 | |
- restart checkpoint-id: 重新装载
checkpoint-id位置的程序状态。所有的程序变量、寄存器、栈帧等都会被恢复为在保存该checkpoint时的状态。实际上,GDB类似于将时间拨回到保存该checkpoint的时间点。
注意,对于breakpoints、GDB variables、command history等,在执行恢复到某个checkpoint时并不会受到影响。一般来说,checkpoint只存储调试程序的信息,而并不存储调试器本身的信息。
- delete checkpoint checkpoint-id: 删除以前保存的某个checkpoint
返回到前一个保存的checkpoint时,将会恢复该调试程序的用户状态,也会恢复一部分的操作系统状态,包括文件指针。恢复时,并不会对一个文件中的数据执行un-write操作,但是会将文件指针恢复到原来的位置,因此之前所写的数据可以被overwritten。对于那些以读模式打开的文件,文件指针将会恢复到原来所读的位置。
当然,对于那些已经发送到打印机(或其他外部设备)的字符将不能够snatched back,而对于从外部设备(例如串口设备)接收到字符则从内部程序缓冲中移除,但是并不能push back回串行设备的pipeline中。相似的,对于文件的数据发生了实质性的更改这一情况,也是不能进行恢复。
然而,即使有上面的这些限制,你还是可以返回到checkpoint处开始进行调试,此时可能还可以调试一条不同的执行路径。
最后,当你回退到checkpoint时,程序会回退到上次保存时的状态,但是进程ID会发生改变。每一个checkpoint都会有一个唯一的进程ID,并且会与原来程序的进程ID不同。假如你所调试的程序在本地保存了进程ID的话,则可能会出现一些潜在的问题。
3.1 使用checkpoint的潜在优势
在有一些系统上,比如GNU/Linux,通常情况下由于安全原因每一个新进程的地址空间都是随机的。这就使得几乎不太可能在一个绝对的地址上设置一个breakpoint或者watchpoint,因为在程序下一次重启时,程序中symbol的绝对路径可能发生改变。
然而一个checkpoint,等价于一个进程拷贝。因此假如你在main的开始就创建一个checkpoint,后续返回到该checkpoint而不是重启程序,这就可以避免受到重启程序地址随机这一情况的影响。通过返回checkpoint,可以使得程序的symbols仍保持在原来的位置
3.2 checkpoint使用示例
1) 示例程序
1 | |
2) 调试技巧
首先采用如下的命令编译程序:
1 | |
下面我们进行调试,在ret += func1()前保存一个checkpoint:
1 | |
然后使用next步进,并每次调用完毕,打印ret的值:
1 | |
结果发现,在调用func2()后,ret的值变为了1。可是此时,我们已经错过了调试fun2()的机会。如果没有checkpoint,就需要再次从头调试了。对于这个问题从头调试很容易,但是对于很难复现的bug可能就会比较困难了。
下面我们使用checkpoint恢复:
1 | |
上面我们看到,GDB恢复到了保存checkpoint时的状态了。上面restart 1中1为checkpoint的ID号。
从上面我们看出checkpoint的用法很简单,但是很有用。就是在平时的简单的bug修复中,也可以加快我们的调试速度,毕竟减少了不必要的重现bug的时间。
多线程调试——参考资料
应用示例
使用 GDB 查看程序的栈空间
由于我们并不知道一个程序的栈空间有多大,所以我们在查看栈空间的时候只好去猜测一个数字。使用命令 x 来查看栈空间。
1 | |
查看 $sp 寄存器的值,然后查看栈空间的前 40 行。结果如下:

x是红色字体,并且起始地址是0x7fffffffe27cheap_string是蓝色字体,起始地址是0x7fffffffe280stack_string是紫色字体,起始地址是0x7fffffffe28e

这些字节实际上应该是从右向左读:因为 x86 是小端模式,因此,heap_string 中所存放的内存地址 0x5555555592a0
使用 GDB 查看程序的栈空间——参考资料
热调试程序
热调试程序,是指在程序运行过程中,不用重新编译程序,而是通过 GDB 的命令,实时修改程序的源代码,并立即生效。
热调试的关键在于 GDB 的一种语法:
1 | |
下面使用一个例子来说明热调试的用法:
引言
程序调试时,你是否遇到过下面几种情况:
1、经过定位,终于找到了程序中的一个BUG,满心欢喜地以为找到了root cause,便迫不及待地修改源码,然后重新编译,重新部署。但验证时却发现,真正的问题并没有解决,代码中还隐藏着更多的问题。
2、调试时,我们找到代码中一个可疑的地方,但是不能100%确定这真的就是个BUG。要想确定,只能修改源码、重新编译、重新部署,然后重新运行验证。
3、已经找到了root cause,但不确定解决方案是否能正常工作,为了验证,不得不反复地修改代码、编译、部署。
对于大型项目,编译过程可能需要几十分钟,甚至几个小时,部署过程则更为复杂漫长!可想而知,如果调试过程中,不得不反复的修改源码,然后重新编译和部署,会是一项多么繁琐和浪费时间的事情!
那么,有没有一种更高效的调试手段,可以避免反复修改代码和编译呢?
当然有!本文将介绍一种GDB调试技巧,可以一边调试,一边修复Bug,可以在不修改代码、不重新编译的前提下即可修复BUG,验证我们的解决方案,大幅提高调试效率!
本文预期效果
如下图,冒泡排序程序中,有三个BUG:

冒泡排序示例
图中已经把三个BUG都标注了出来。正常编译运行时,程序执行结果如下:
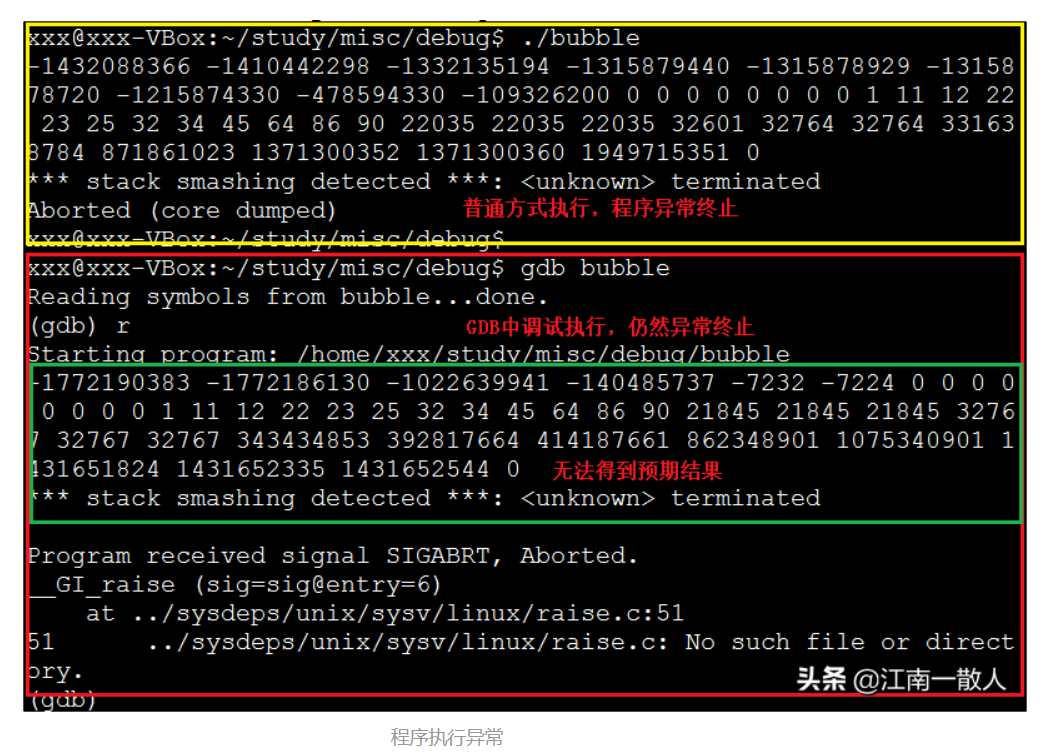
程序执行异常
不过是普通方式执行,还是在GDB中执行,程序都异常终止,无法得到正常结果。
但是,利用本文介绍的调试技巧,可以利用GDB给这个程序制作一个“热补丁”,在不修改代码、不重新编译的前提下,解决掉程序中的三个BUG,让程序正常执行,并得到预期结果!
最终效果,如下图所示:

打上“热补丁”后,程序正常执行
是不是很有趣呢?下面开始介绍!
GDB Breakpoint Command Lists
GDB支持断点触发后,自动执行用户预设的一组调试命令。使用方法:
1 | |
其中:
commands是GDB内置关键字
bp_id是断点的ID,也就是info命令显示出来的断点Num,可以指定多个,也可以不指定。当不指定时,默认只对最近一次设置的那个断点有效。
command-list是用户预设的一组命令,当bp_id指定的断点被触发时,GDB会自动执行这些命令。
end表示结束。
这个功能适用于各种类型的断点,如breakpoint、watchpoint、catchpoint等。
适用场景举例
利用GDB breakpoint commands lists这个特性可以做很多有趣的事情,本文仅列举其中的几个。
1、随时随地printf,不需修改代码和重新编译
看过我之前文章的朋友,应该还记得,我介绍过GDB的动态打印(Dynamic Printf)功能,可以用dprintf命令在代码的任意地方添加动态打印断点,并自动执行格式化打印操作,从而无需修改代码和重新编译就可以在代码中任意增加日志打印信息。
利用GDB breakpoint commands lists功能,可以实现一样的功能,而且除了打印之外,还可以做其它更多的操作,比如dump内存,dump寄存器等。
2、修改代码执行逻辑,避免修改代码和重新编译
在GDB中可以做很多有趣的事情,比如修改变量、修改寄存器、调用函数等,结合breakpoint command list功能,可以在调试的同时,修改程序执行逻辑,给程序打上“热补丁”。从而可以在调试过程中,快速修复Bug,避免重新修改代码和重新编译,大大提高程序调试的效率!
这是本文重点讲解的场景,稍后会演示如何利用这个功能,在GDB调试的过程中修复掉上文冒泡排序程序中的三个Bug。
3、实现自动化调试,提高调试效率
这个功能,结合GDB支持的脚本功能,以及自定义命令功能,可以实现调试自动化。
这涉及到GDB的很多其它知识,篇幅有限,不再展开讨论,以后更新专门文章讲解!感兴趣的童鞋,不妨右上角关注一下!
给冒泡排序打上“热补丁”
现在,我们利用GDB breakpoint command lists功能,给文中的冒泡排序程序打上“热补丁”,演示如何在不修改源码、不重新编译的前提下,解决掉程序中的3个BUG。
再看一下示例程序:

编译一下:
1 | |
先用GDB加载运行一下:

程序运行异常,符合我们的预期。
下面我们依次解决冒泡排序程序中的3个BUG。
1、解决第一个BUG
先解决第22行的BUG,也就是传递给了bubble_sort()错误的数组长度。
我们知道,在x64上,函数参数优先采用寄存器传递。那么,我们有这么几种方式可以选择:
把断点设置在bubble_sort()入口第一条指令,然后直接修改存放数组长度n的那个寄存器中的值。
把断点设置在bubble_sort()入口处(不必是第一条指令),在第7行for循环之前,把存放数组长度的变量n的值改掉。
把断点设置在main()函数第22行,也就是调用bubble_sort()的地方,然后以正确的参数手动调用bubble_sort()函数,并利用GDB的jump命令,跳过第22行代码的执行。
考虑到有些童鞋对x64 CPU不是非常了解,或者对GDB的jump命令不熟悉,我们采用第2种方式。而且,这种方式也更简单通用。
我们先给bubble_sort()函数设置断点,然后利用commands命令预设一条命令,把变量n的值修改为10。命令如下:
1 | |
设置完之后,用run命令开始运行程序。结果如下:

bubble_sort()处的断点被触发后,程序暂停,用print命令查看变量n的值,已经被修改成了正确的值:10。
可见,我们的设置是有效的。
断点触发后,让程序自动恢复执行
那么,在bubble_sort()处断点被触发,变量n的值被修改之后,如何让程序自动恢复执行呢?
很简单,只需要在预设的命令中添加一个continue命令就可以了。为了证明我们的设置确实是生效的,我们在修改变量n的前后,各添加一个格式化打印语句,把变量n的值打印出来:
1 | |
结果如下图:

解决第一个BUG
从运行结果可以看出,断点被触发后,我们预设的语句被正确执行,变量n的值被修改为10,然后程序自动恢复执行。
到此,第一个BUG已经解决了。
2、解决第二个BUG
下面,我们解决第7行代码中的数组访问越界错误:数组的元素个数是n,但是bubble_sort()中第一个for循环的终止条件是i<=n,明显会造成访问越界,正确的条件应该是i<n。
要解决这个BUG也很简单,只需要在执行第8行代码之前,判断如果i的值等于n,就跳出循环。对于这个简单的程序,我们直接从bubble_sort()函数return就可以了。
命令如下:
1 | |
在第8行设置条件断点,当i==n时断点被触发,然后自动把i和n的值打印出来,再行return命令,从bubble_sort()返回,然后continue命令自动恢复程序执行。
执行结果如下图:

解决第二个BUG
3、解决第三个BUG
下面,解决最后一个BUG,第23行数组访问越界错误。
命令如下:
1 | |
与第二个BUG类似,在第24行设置条件断点,当==10时触发断点,然后退出循环,让程序跳转到第26行继续执行。
执行结果如下图所示:

解决第三个BUG
从图中可以看出,三个断点全部被触发,并且预设的命令都正常执行。
我们终于得到了正确的执行结果!
虽然,现在程序可以正常执行了,但是每次手动输入命令还是比较麻烦的。我之前文章介绍过,GDB支持调试脚本,从脚本中加载并执行调试命令。
下面,我们利用GDB脚本,来制作我们的“热补丁”脚本。
制作“热补丁”脚本
我们把上文中用来解决三个BUG的命令保存在一个脚本文件中:
1 | |
脚本内容如下图:

bubble.fix 热补丁脚本
bubble.fix脚本中的命令,与上文在GDB中直接输入的命令有几个区别:
删除了格式化打印信息。
删除了commands后面的断点ID。上文讲过,commands后面的断点ID可以省略,表示对最近一次设置的断点有效。为了让脚本更加通用,每个commands都紧跟在break命令之后,因此直接省略了断点ID。
GDB的脚本可以通过两种方式执行:
启动GDB时,用-x参数指定要执行的脚本文件。
启动GDB后,执行source命令执行指定的脚本。
下面,我们用第二种方式演示一下,如下图所示:

执行bubble.fix脚本
使用source命令加载并执行bubble.fix,然后用run命令执行程序,三个断点均被触发,且预设的命令全部被正确执行,最后程序运行正常,得到期望的结果!
我们现在可以利用我们制作的“热补丁”脚本,在不修改代码、不重新编译和部署的前提下,成功修复程序中的BUG!是不是很有趣呢?
不过,做到这种程度,还不算完美!
尽管得到了正确的结果,但程序执行时,总是会打印我们设置的断点信息,看起来还是有些视觉干扰的。
最后,我们来解决这个问题,让我们的“热补丁”更加完美!
优化“热补丁”脚本,隐藏断点信息
在预设的命令中,如果第一条命令是silent,断点被触发的打印信息会被屏蔽掉。
我们把bubble.fix做些修改,把silent命令加进去,如下图所示:

最终版bubble.fix 脚本
然后,重新执行一下:
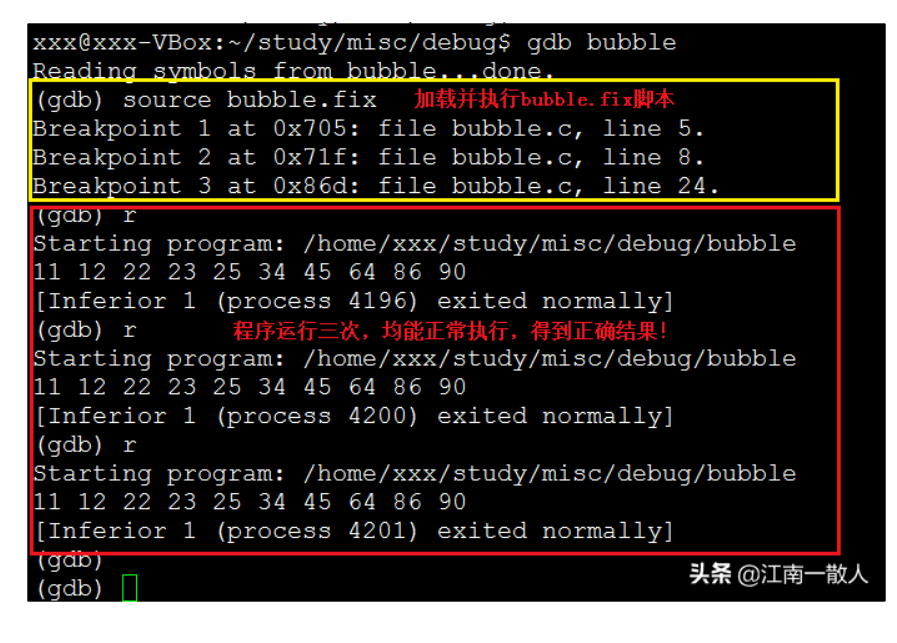
这样,看起来,清爽多了!
到此,我们终于实现了本文的目标:一边debug,一边修复BUG,避免反复修改代码、重新编译和部署、提高调试效率!
结语
本文重点介绍了如何利用GDB breakpoint command lists功能,制作“调试热补丁”,修改代码BUG。还可以利用这个功能,快速验证我们的猜想和解决方案,避免反复修改代码和重新编译。
巧用GDB breakpoint command lists功能,可以做很多有趣的事情,如实现调试自动化,提高调试效率等。